The Optical Character Recognition (OCR) respectively Document Capture software market size is expected to be USD 12.6 billion by 2027 with a year on year growth of approx. 10%. The increasing demand for document extraction software solutions is mainly due to compliance initiatives, the digitalization of document management and intentions to optimize operational costs. But also because of the increasingly mobile workforce and the often associated need for document processing via mobile devices. Although OCR has been considered a solved problem by a wide range of people, there are yet many challenges to solve. Handwriting Recognition or Handwritten Text Recognition (HTR) being one of them. The high variance in handwriting styles across people and poor quality of the handwritten text compared to machine-printed text pose significant obstacles in converting it to machine-readable text formats. Nevertheless, it’s a crucial problem to solve for multiple industries like healthcare, insurance and banking and therefore, Parashift’s R&D activities in full swing.

Relatively recent advancements in Deep Learning such as the advent of transformer architectures have fast-tracked our progress in solving handwritten text recognition. In the industry, we usually speak of Intelligent Character Recognition (ICR) when talking about recognizing handwritten text. This due to the fact that the algorithms needed to solve ICR need much more “intelligence” than solving generic OCR.
In this article, we will be learning about the task of handwritten text recognition, its intricacies and how we can solve it using different deep learning techniques.
Main challenges in recognizing handwritten text
- Tremendous variability and ambiguity of strokes from person to person
- Inconsistency in writing style
- Poor quality of the source document due to degradation over time
- Oftentimes text is not written in a strictly straight line
- Cursive handwriting makes separation and recognition of characters even more challenging
- Text in handwriting can have a variable rotation
- Collecting a high-quality dataset with labels is relatively expensive
Use cases
Healthcare and pharmaceuticals
One of the main pain points in the healthcare and pharmaceutical industry is the digitalization of patient prescriptions. For example, Roche is handling an incredible amount of medical PDFs every day. Also the patient enrollment and other form digitalization cases are requiring a reliable solution to recognize and extract handwritten text. So, by adding handwriting recognition to their operations and business processes, healthcare and pharmaceutical institutions can significantly improve their process efficiency and customer experiences.
Insurance
Looking at the insurance sector, a large insurance company can easily receive a couple of millions of documents on a single day and a delay in processing, for example, claims can impact the company in a very meaningful way. The claim documents which can contain various different handwriting styles are regularly processed purely manually. Hence, the automation of claims processing has a major bottleneck here.
Banking
I know it may be hard to believe but people actually still write cheques on a regular basis and so these kinds of documents still play a major role in most non-cash transactions. In some countries more than in others of course. Having said that, in many developing countries, the current cheque processing procedure requires a bank employee to read and manually enter the information present on a cheque and also verify the entries like, for example, signature and date. As in most cases, these cheques are being centralized for processing, it’s quite common that a large number of such cheques have to be processed day in and day out. In other words, here again, a powerful handwriting text recognition system could save significant hours of human work and bring about dramatic cost savings.

Online Libraries
Another area where HTR comes into play is in online libraries. Cause here, incredible amounts of historical writings are being digitized by uploading scans, creating access for people all around the world. However, because of the huge amount of data, such endeavors are only truly useful when one can identify the text on these scans, index them and make queries, etc.

Methods
Broadly speaking, handwriting recognition methods can be classified into two different types:

When we do online handwriting recognition, the methods involve a digital pen and through that, we have access to the stroke information and pen location while text is being written. The picture above is a very good illustration of this and should also indicate that for these writings, we usually have a good amount of information which makes it a whole lot easier to classify characters with higher accuracy.
Offline methods, on the other hand, involve recognizing text once it’s written down and based on this information only. Thus, we have much more scarce features to use for making predictions. Even worse, we might also have to deal with background noise emanating from the paper.
If in real-world scenarios it wouldn’t so hard to properly scale the digital pen approach, the task of recognizing handwritten text wouldn’t be that big of a deal anymore. But as it is just the way it is, we have to find solutions that help us make sense of the information we have provided by non-digital pens. That’s why we now will look at various techniques to solve the problem of recognizing offline written text.
Some of the techniques
The first approaches to solving handwriting recognition involved Machine Learning methods such as well know Hidden Markov Models (HMM), Support Vector Machines and the like. These approaches focused on feature extraction after an initial pre-processing of the text. These features could for example be things like loops, inflection points, ratios of some sort and other aspects of a single character. Once extracted, the features are fed to a classifier such as the HMM with the aim of getting good results. However, such approaches are heavily relying on manual work for feature extraction akka not scalable and are pretty limited in terms of learning capacity. As a result, the performance of these kinds of Machine Learning models is rather limited.
But there is good news: as touched upon at the beginning, Deep Learning has opened up a completely new spectrum of possibilities to tackle the existing problems and brought about tremendous improvements in accuracy for handwriting recognition. In the following, I will go into some of the most prominent research in this particular field.
Multi-dimensional Recurrent Neural Networks
Recurrent Neural Networks (RNN) or Long Short-Term Memory (LSTM), which is a specific RNN architecture, are known to be able to deal with sequential data to identify temporal patterns and generate results. At least the most common configurations of these kinds of architectures. Nevertheless, there’s a significant limitation: they can only handle 1D data and as a consequence, these architectures can’t be applied to image data directly. To address this problem, the authors of the paper “CITlab ARGUS for Arabic Handwriting” proposed a multi-dimensional RNN/LSTM structure as visualized below.
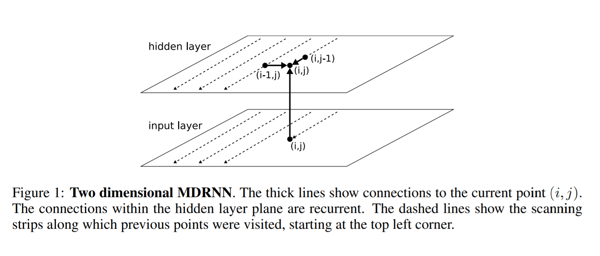
So, what is the difference between a traditional RNN and the proposed multi-dimensional RNN… Usually, in general RNNs, hidden layer i receives state from a previous hidden layer in time i-1. But in cases of multi-dimensional RNNs, let’s take the example of a 2-dimensional RNN structure, the hidden layer (i, j) receives states from multiple previous hidden layers, being (i-1, j) and (i, j-1). Therefore, such architectures capture context from both height and width in an image which is pivotal for getting a clear understanding of the local region. You can further extend that to also get information from future layers. So, this is pretty similar to how Bidirectional Long Short-Term Memory (BI-LSTM) networks receive information from both t-1 and t+1. To get back to our hypothetical 2-dimensional RNN structure, here we would now be able to receive information in both directions as well, e.g. (i-1, j), (i, j-1), (i+1, j), (i, j+1) and thus, capturing context in all directions just as with the BI-LSTM.
What you can see in the figure below is basically the entire multi-dimensional RNN structure. So, what we do is simply replace the RNN block with an LTSM block. The network’s input is divided into blocks of size 3×4 which is fed into the multi-dimensional RNN layers respectively the network’s hierarchical structure of multi-dimensional RNN layers followed by feed-forward layers in tandem. Feed-forward layers being classical artificial neural networks. The final output is converted into a 1D vector and is passed to a Connectionist Temporal Classification (CTC) function to generate an output.
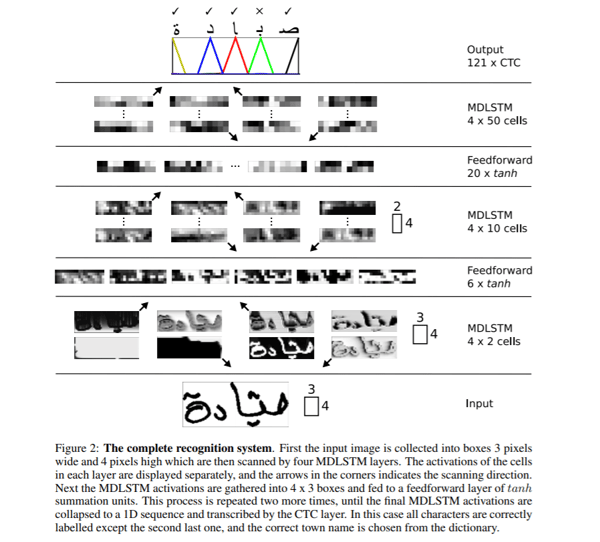
CTC is an algorithm used to deal with tasks such as speech recognition and handwriting recognition. Both of them are tasks where just the input data and the output transcription is available and no alignment details are provided. Meaning, how a particular region in audio for speech or a particular region in images for handwriting is aligned to a specific character. The issue here is that simple heuristics such as giving each character the same area won’t work as the amount of space each character takes varies greatly in handwriting styles. A good resource for more information on how CTC works can be seen here.
When we decode the output of a CTC using simple heuristics of the highest probability for each position, we might get results which might not make lots of sense in real-world cases. That’s why we might have to use another kind of decoder which is more promising to improve our results. In order to get a better understanding of the decision-making, let’s consider the different types of decoding there are:
- Best-path decoding is the generic decoding we have implicitly discussed so far. In this type, at each position, we take the output of the model and simply find the result with the highest probability.
- When shooting for beam search decoding, the beam search suggests keeping multiple output paths with the highest probabilities and thereby expands the chain with new outputs while dropping paths with lower probabilities to keep the beam size constant.
- Beam search usually provides more accurate results than grid search. But there is still more room to get truly meaningful results. A way to aim for greater performance is to use a language model alongside beam search using both probabilities from the model and the language model (which, for example, scores character-sequences according to probabilities) to generate the final results.
More details about generating accurate decoding results can be consulted in this article.
Encoder-decoder and attention networks
Seq2Seq models (sequence to sequence) having encoder-decoder networks have recently been popular for solving the tasks of speech recognition or also machine translation and have been applied to solve the use case of HTR by deploying an additional attention mechanism. Let’s take a closer look at some recent research in this area.
Scan, attend and read
In the paper “Scan, Attend and Read: End-to-End Handwritten Paragraph Recognition with MDLSTM Attention” the authors propose the usage of an attention-based model for end-to-end multi-line handwriting recognition. The main contribution of the research is the automatic transcription of text without having to segment it into lines as a pre-processing step and as a result, can simply scan an entire page and provide results directly.
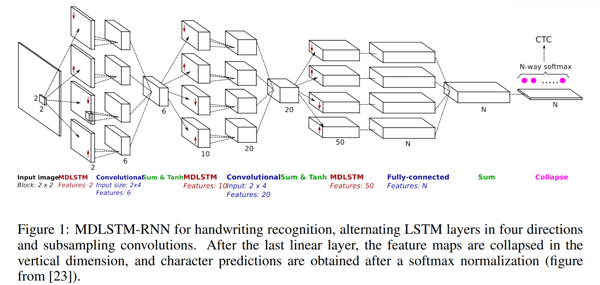
Scan, attend and read (SAR) uses a multi-dimensional long-term short-term memory (MDLSTM)-based architecture similar to the one we already discussed before with one difference in the final layer. After the last linear layer, meaning the final sum block in the figure above, the feature maps are collapsed in the vertical dimension and a softmax function is applied to get the outputs.
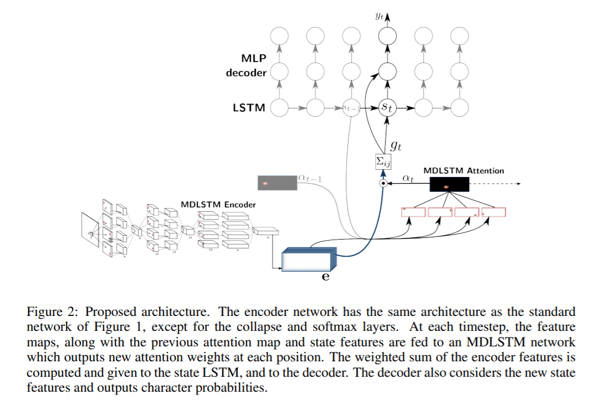
The SAR architecture consists of an MDLSTM architecture which acts as the feature extractor. The final collapsing module with an implemented softmax output and CTC loss is replaced by an attention module and an LSTM decoder. The attention model applied is a hybrid combination of content-based attention and location-based attention. What this really means can be read in the paper we will discuss next. In general, attention mechanisms let a model directly look at, and draw from, the state at any earlier point, allowing it to focus on the most relevant encoded features at each decoding step. The decoder LSTM modules, on the other hand, take the previous state, previous attention map and the encoder features in order to generate an output character and the state vector for the next prediction.
Convolve, attend and spell
The paper “Convolve, Attend and Spell: An Attention-based Sequence-to-Sequence Model for Handwritten Word Recognition” proposes an attention-based sequence-to-sequence model. The architecture proposed has three main parts: an encoder, consisting of a convolutional neural net (CNN) and a bi-directional GRU, an attention mechanism devoted to focusing on the pertinent features and a decoder formed by a one-directional GRU, able to spell the corresponding word, character by character.
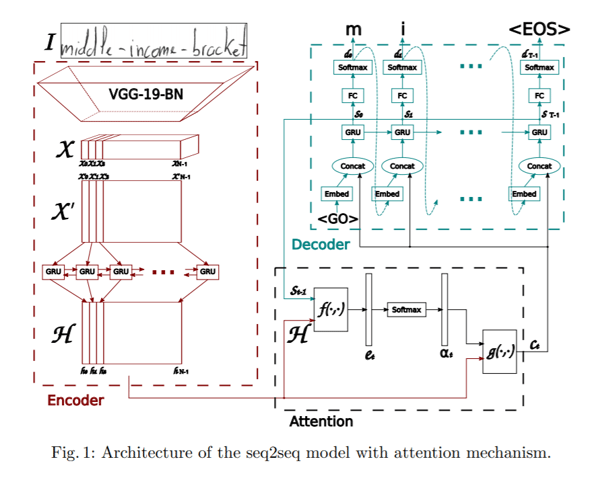
The encoder uses a CNN to extract low-level visual features. Specifically, a pre-trained VGG-19-BN (basically a 19 layers deep network, batch normalized) architecture is used as a feature extractor. The input image is thereby converted into feature map X which is then reshaped into X’ by splitting all channels column-wise and combining them to get the sequential information. X’ is further converted to H by using a bi-directional GRU. GRU is a neural network similar to LSTM in nature and can capture temporal information.
Further, an attention model is applied while predicting the output from the decoder, an RNN decoding one character at each time step, thus spelling the whole word. The authors discuss two different types of attention mechanisms they explored.
- Content-based attention: The idea behind this methodology is to find the similarity between the current hidden state of the decoder and the feature map from the encoder. We can find the most correlated feature vectors in the feature map of the encoder, which can be used to predict the current character at the current time step. A more intuitive way of looking at how attention mechanisms work can be found here.
- Location-based attention: The main disadvantage of location-based mechanisms is that there is an implicit assumption that the location information is embedded in the output of the encoder. Otherwise, would be no way to differentiate between character outputs that are repeated from the decoder. But let’s look at an example to make things more clear. Let’s assume we have the word Parashift, in which the character a is repeated twice. Without location information, the decoder cannot predict them as separate characters. To address this problem, the current character and its alignment are predicted by using both the encoder output and previous alignment. If you are curious about how the methodology works in greater detail, you can dig deeper here.
The decoder is a one-directional multi-layered GRU. At each time step, t it receives input from previous time step and the context vector from the attention module. Multinomial Decoding and label smoothing are explored at training to improve generalization capability.
Transformer models
So, encoder-decoder networks have been astonishingly good in handwriting recognition. Nevertheless, these kinds of networks yet do have a significant bottleneck in the training process due to the LSTM layers involved. Therefore, training can’t run in parallel. Not too long ago, however, transformer models have proven to be very promising and actually replaced LSTM structures in solving some language-related tasks. Thus, the question arises, how can we apply these to our handwriting recognition tasks?
Pay attention to what you read
In the paper “Pay Attention to What You Read: Non-recurrent Handwritten Text-Line Recognition“, the authors introduce a non-recurrent approach by instead using a transformer-based architecture and multi-headed self-attention layers at both visual and textual stages. Thereby, they can learn both character recognition as well as language-related dependencies of the character sequences to be decoded. Since the language knowledge is embedded into the model itself, there is no need for any additional post-processing step using a language model. Or in other words, no vocabulary is necessary to be able to predict outputs. In order to achieve this, text encoding happens at a character and not a word level. As the transformer architecture allows parallelized training for every region or character, the training process is much simpler.
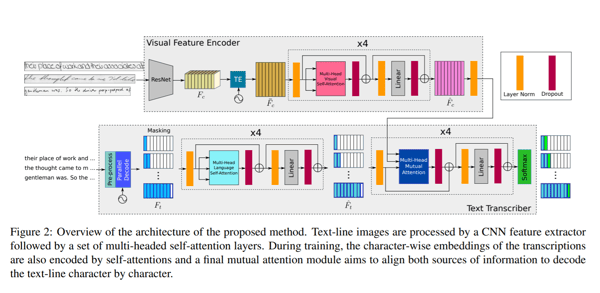
The network architecture proposed in the paper consists of two major components. A visual encoder, extracting relevant features and applying multi-headed visual self-attention on different character locations and a text transcriber, which takes text input, encodes the text, applies multi-headed language self-attention and mutation attention on both visual and textual features.
Visual encoder
The authors use the ResNet50 as a backbone convolutional architecture to extract the features (visualized in the figure above). The 3-dimensional feature representation from ResNet50 is passed to a Temporal Encoding (TE) module which reshapes to 2D by keeping the same width and thus, the shape of (f x h, w). This is fed into a fully connected layer to reduce the shape to (f, w) and the resultant output is Fc’, which can be seen as a w-length sequence of visual vectors. In addition, a positional encoding TE is added to Fc’ to retain the position information. The output is passed through a fully connected layer to get the final feature representation with shape (f , w). The final output is passed through a multi-headed attention module with 8 heads to get a visually rich feature map. To learn more about transformer models, click here.
Text transcriber
The second part of the proposed methodology is a text transcriber. There, eh text is passed through an encoder that generates character-level embeddings. These embeddings are combined with temporal location similar to the way in the visual encoder, using a TE module. The values are then passed to a multi-head language self-attention module, which is again similar to the module applied in the visual encoder. The text features generated along the visual features from the visual encoder are passed to a mutual-attention module whose sole task is to align and combine the learned features from both images and the text inputs. Finally, the output is passed through a softmax function.
Handwriting text generation
So get back to a more general level again, let’s look at handwriting text generation. As you may guess, this is all about generating synthetic handwritten text or in other words, augmenting existing datasets, which are scarce. To properly go about such kinds of meaningful data augmentations, we can make use of generative adversarial networks.
ScrabbleGAN
ScrabbleGAN is a proposed method that follows a semi-supervised approach to synthesize handwritten text images that are versatile in both style and lexicon. The approach relies on a novel generative model which can generate images of varying length. The generator also can manipulate the resulting text style which allows us to decide whether the text has to be cursive or say how thick or thin the stroke should be.
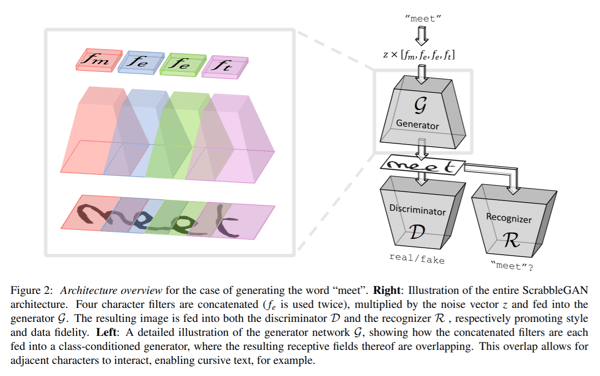
The architecture consists of a fully convolutional generator based on BigGAN. For each character in the input, a corresponding filter is selected from a filter-bank before all the values are concatenated together and then multiplied by a noise vector z that controls the generated text style. As illustrated in the figure above, the regions generated for each individual character overlap, helping in generating connected recursive text as well as allowing the flexibility of different characters sizes. As an example, “m” takes up quite a bit of space while the “e”s not so much. To keep the same style for the entire word or also sentence, the noise vector z is kept constant for all characters.
To classify whether the generated style of an image is fake or real, a convolutional discriminator based on a BigGAN architecture is implemented. As the discriminator is not relying on character-level annotations, it is not based on a class conditional GAN. The advantage of this is that there is no need for labeled data and so even unlabeled data from unseen corpora can be used for training the discriminator. Along with the discriminator a text recognizer R is trained to classify if the text generated is real or if it’s gibberish. The recognizer is based on a convolutional recurrent neural network (CRNN) architecture. The text generated in the output of R is then compared with the input text given to the generator and a corresponding penalty is added to a loss function.
Some of the outputs generated by ScrabbleGAN are displayed here:

Summary
We have experienced many fundamental breakthroughs in the past years and yet, despite all this progress in the underlying technologies, HTR is far from being a solved problem. However, given recent trends on how fast we can move forward, this might change relatively soon. And just to mention that as well… Already today we can provide companies meaningful technology that can help reduce manual efforts significantly.
If you’re curious to learn more about Parashift’s functionalities in that regard, feel free to reach out. We are happy to give you a more in-depth introduction to what our extraction engine is capable of dealing with.
