Dieser Artikel wurde von unserem ML-Team verfasst.
Dies ist der Beginn einer mehrteiligen Blog-Miniserie, in der wir einen Einblick geben, wie wir bei Parashift ML/KI einsetzen, um Probleme im Bereich der intelligenten Dokumentenverarbeitung (kurz IDP für Englisch intelligent document processing) zu lösen.
Die ersten beiden Teile bieten eine kurze Einführung in allgemeine Schlüsselthemen und Konzepte der KI, ohne dass der Fokus speziell auf Parashift liegt. Wir beginnen mit der Diskussion über den Unterschied zwischen diskriminierenden und generativen Modellen. Im dritten Teil gehen wir auf unsere aktuellen Bemühungen ein, LLM-Antworten in den Dokumenten zu verankern. Der Begriff „Verankerung“ beschreibt hier die Fähigkeit, die Antwort eines LLM mit expliziten Tokens im Dokument zu verknüpfen. Der vierte Teil beleuchtet weitere Anwendungsbeispiele beider Methoden in unserem Produkt, und der letzte Teil gibt schließlich einen Ausblick darauf, wohin wir uns als Nächstes entwickeln möchten.
Diskriminierende KI-Modelle vs. Generative KI
Zunächst betrachten wir zwei verschiedene Arten von KI-Modellen und beginnen mit einer Einführung, um die konzeptionellen Unterschiede hervorzuheben. Wie wir sehen werden, beeinflussen diese Unterschiede, wie und wo wir die Modelle in der Praxis einsetzen.
Diskriminierende KI-Modelle
Diese Modelle lernen, wie man „Dinge“ unterscheidet. Stellen Sie sich diese Modelle als „Label-Maschinen“ vor: Sie zeigen dem Modell ein Objekt, und es weist ihm ein bestimmtes Label sowie eine Zahl zu. Das Label bestimmt, als was das Objekt klassifiziert wurde, und die Zahl reflektiert das Vertrauen in diese Klassifizierung. Ein gängiges Beispiel ist ein Bildklassifizierer, der Tiere identifiziert. Wenn dieses Modell zum Beispiel auf 100 verschiedenen Tierarten trainiert wurde, kann es am Ende nichts weiter, als Bilder betrachten und das bestpassende Label zuweisen. Es kann keine neuen Labels erzeugen, sondern ist auf die Labels beschränkt (und dadurch beeinflusst), die es während des Trainings gesehen hat.
Viele IDP-Aufgaben lassen sich so formulieren, dass ein diskriminierendes Modell trainiert werden kann, um sie zu lösen. Der Ansatz läuft dann immer darauf hinaus, einem Objekt ein Label zuzuweisen. Die Anwendungsfälle unterscheiden sich darin, welche Labels vergeben werden und auf welche „Dinge“ sie angewendet werden. In den folgenden Beispielen erhöhen wir schrittweise die Granularität dieser Label-Zuweisungen und zeigen, wie unterschiedliche Aufgaben damit gelöst werden können.
Dokumentenklassifizierung (ein Label pro Dokument)
Der einfachste Anwendungsfall: Während des Trainings werden dem Modell Dokumente (und ihre Labels) verschiedener Dokumententypen gezeigt, damit es lernt, diese zu unterscheiden. Die Labels entsprechen allen Dokumenttypen, die wir unterscheiden müssen (z. B. „Rechnung“, „Reisepass“, „Fitnessstudio-Mitgliedskarte“ usw.). Obwohl die Aufgabe klar definiert ist, gibt es viel kreativen Spielraum, wie das Modell trainiert wird – z. B. anhand visueller Merkmale, textlicher Merkmale oder einer Kombination von beiden.

Trennung von Seitensstapeln (ein Label pro Seite)
Nun starten wir mit einer geordneten Seitensstapel, die Aufgabe es ist zu erkennen, welche Seiten zusammengehören, um ein eigenständiges Dokument zu bilden. Dies ist besonders nützlich, wenn physische Post eingescannt wird, und als ein einziges großes PDF, das alle Dokumente umfasst erstellt wird.
Wir entschieden uns für einen Ansatz, bei dem das Modell zwei Labels vorhersagt: „erste Seite“ oder „letzte Seite“. Auf Grundlage dieser Vorhersagen lässt sich ableiten, wo der Seitensstapel in einzelne Dokumente aufgeteilt werden soll. Unten sehen Sie ein schematisches Beispiel eines Seitenstapels mit 6 Seiten, die zu 3 Dokumenten führt.

Informationsextraktion (ein Label pro Token)
Betrachten wir nun, wie diskriminierende Modelle zur Extraktion von Informationen wie Absender-Adressen, Zahlbeträgen oder Lieferterminen eingesetzt werden können. Aus der Perspektive eines Klassifikationsmodells müssen wir ein System aufbauen, das nur bestimmten Teilen des Dokuments Labels zuweist.
Beispiel: Das Modell kann dem Text „Parashift AG“ das Label „Firmenname“ zuordnen. Ein weiterer Schritt ist das Training eines Modells zur Vorhersage, welche Tokens zusammengehören (sogenannte Link-Prediction). Das Modell entscheidet also, ob „Parashift AG“ eine Einheit ist oder zwei separate, wie „Parashift“ und „AG“ ist.
Embeddings und Tokenisierung
Wir wissen nun, wie sich IDP-Aufgaben für diskriminierende Modelle konzeptionell formulieren lassen. Zwei weitere Konzepte sind für ein besseres Verständnis grundlegend: Embeddings und Tokenisierung.
Da die Aufgabe darin besteht, „Dingen Labels zuzuweisen“, benötigen wir eine Möglichkeit, die „Dinge“ sinnvoll darzustellen – sei es ein Dokument, eine Seite oder einzelne Tokens innerhalb eines Dokuments. Hier kommen nun Embeddings ins Spiel.
Embeddings
KI-Modelle arbeiten nicht direkt mit Bildern, Audio, Dokumenten, Text oder Tokens, wie wir Menschen sie verstehen. Sie verarbeiten ausschließlich Zahlen. Die Umwandlung realer Objekte in eine „Liste von Zahlen“ nennt man Embedding oder Vektorisierung. Wichtig ist, dass diese Zahlen eine sinnvolle Repräsentation für das zu lösende Problem liefern.
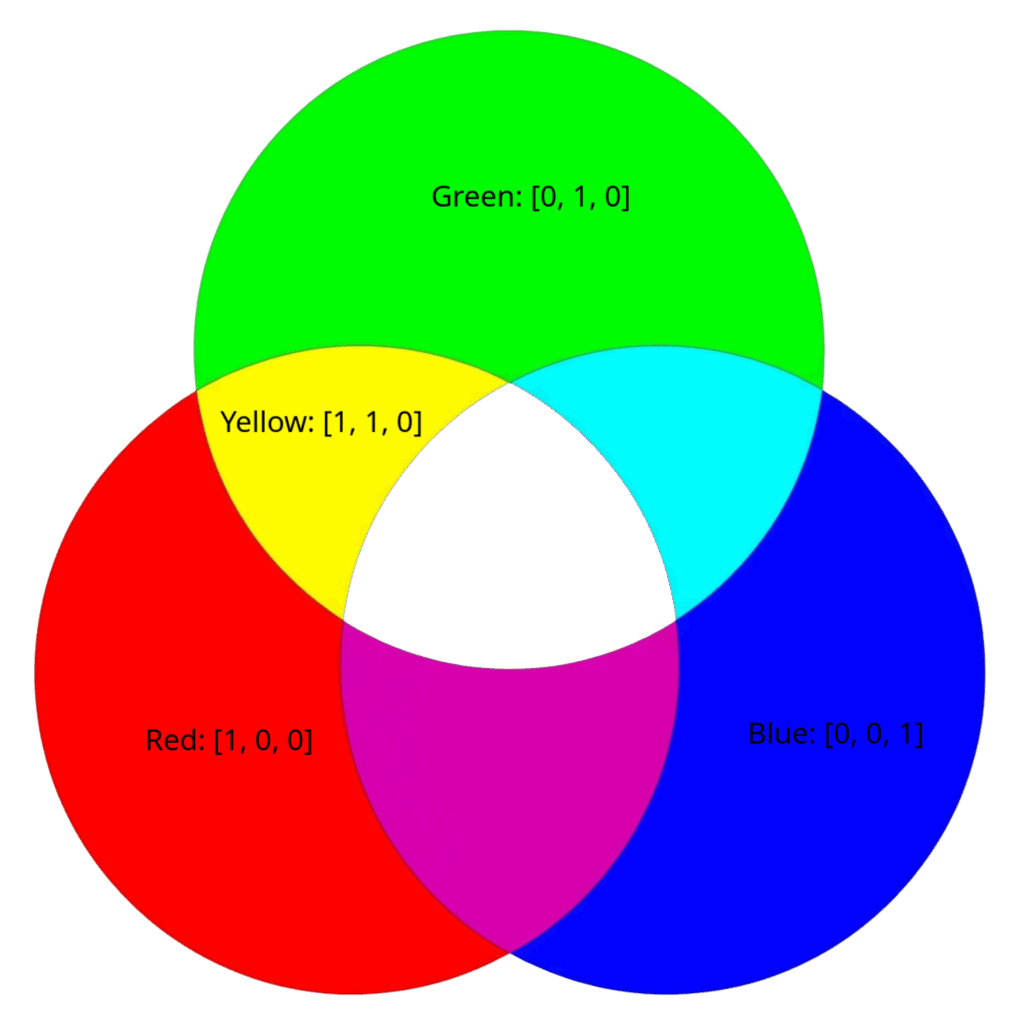
RGB als Beispiel
Dieser Abschnitt ist nicht auf IDP bezogen, sondern veranschaulicht allgemein, wie Informationen in Zahlen übersetzt werden können. Ein Pixel auf Ihrem Bildschirm lässt sich durch drei RGB-Werte darstellen (R = Rot, G = Grün, B = Blau). Dies kann als eine Art Embedding betrachtet werden: [R, G, B]. Für unser Beispiel normalisieren wir die Werte auf den Wertebereich 0–1.
- Rot → [1, 0, 0]
- Grün → [0, 1, 0]
- Blau → [0, 0, 1]
Beliebige Farben lassen sich nun als Kombination dieser drei Zahlen darstellen, z. B. Gelb = Rot + Grün → [1, 1, 0]. Moderne LLMs wie ChatGPT, Claude oder LLaMA verwenden deutlich größere Embeddings, oft mehrere tausend Zahlen pro Token und nicht nur 3 wie in unserem Beispiel.
Nehmen wir an, wir hätten ein Token-Embedding-Modell, das für jedes Token nur drei Zahlen zur Darstellung der Bedeutung verwenden darf – dies aus dem Grund, dass wir wie gesehen 3 Zahlen einfach als Farben visualisieren können. Im fiktiven Beispiel unten sehen wir, dass Adressen einen rötlichen Ton haben, Zahlen grün erscheinen und Datumsangaben blau gefärbt sind.
Bei genauerer Betrachtung gibt es aber auch Ausnahmen: Hausnummern und Postleitzahlen erscheinen nämlich orange. Das heisst, dass das Modell dynamische Embeddings generiert, die sich je nach Kontext ändern. Als Kontext gelten in diesem Fall die benachbarten Tokens. Im Gegensatz dazu sind statische Embeddings feste Lookups: Zum Beispiel das Token „9155“ hätte immer dieselbe Repräsentation, unabhängig vom Kontext.
Bei Parashift kombinieren wir dynamische und statische Embeddings, um LLM-Antworten in Dokumenten zu verankern. Verankerung bedeutet hier: Wir identifizieren die genauen Tokens, die eine Antwort bilden – mit einer Auflösung bis auf Token-Ebene, nicht nur auf Absatz- oder Zeilen-Ebene. Statische Embeddings stoßen an ihre Grenzen, wenn sie Homonyme unterscheiden sollen wie z. B. das Wort „Bank“ in unterschiedlichen Kontexten.
Ich setze mich auf die Bank.
Ich gehe in die Bank.

Tokenisierung
Ein weiterer entscheidender Schritt ist die Aufteilung eines Dokuments in kleinere Einheiten: Absätze, Zeilen, Wörter oder Tokens. Diese Einheiten können dann mit Labels versehen werden.
Ein Token ist meist ein kurzes Wort oder ein Teilwort. Die optimale Methode zur Tokenisierung gibt es in diesem Sinne nicht. Am untenstehenden Beispiel sehen wir, wie der GPT4 Tokenizer einen Satz in Tokens zerstückelt, diese sind als farbige Rechtecke dargestellt. Nach der Tokenisierung können wir jedem Token Labels zuweisen, z. B. Absendername, Absenderstraße, Absenderhausnummer – dies bildet die Grundlage für die Informationsextraktion.

Zum Schluss können ein weiteres Modell trainieren, das diese Embeddings nutzt, um Tokens Labels zuzuweisen. Für „Adressen“ oder „Daten“ funktioniert das in unserem Beispiel sehr gut. Andere Informationen werden schwieriger, wenn die Embeddings die Tokens nicht ausreichend differenzieren kann (viele Tokens sind einfach grau).
Dies verdeutlicht die Notwendigkeit generischer Einbettungen, die eine Vielzahl möglicher nachgelagerter Aufgaben abdecken können, und gleichzeitig genügend Informationen liefern, um die nachfolgenden Klassifikationsmodelle zu unterstützen.
Zusammenfassung diskriminierender Modelle
Vorteile:
- Vorhersagen für jedes Token ermöglichen eine exakte Identifikation der entsprechenden Inhalte direkt im Dokument.
- Jede Vorhersage kommt mit einem Konfidenzwert, der die Zuverlässigkeit der Klassifizierung angibt.
- Modelle sind vergleichsweise klein (einige Millionen bis wenige hundert Millionen Parameter) und können auf einer einzigen GPU in Minuten bis Stunden trainiert werden.
- Kleine Modelle sind schnell: Dokumente mit wenigen Seiten werden in Millisekunden verarbeitet.
- Datenschutz: Die Modelle geben keine sensiblen Trainingsdaten preis. Sie fügen lediglich Labels hinzu.
- Embedding-Modelle erledigen den Großteil der „schweren Arbeit“, und die Embeddings können dann für mehrere verschiedene Aufgaben wiederverwendet werden.
Nachteile:
- Sie können ihre Antworten nicht auf neue, ungesehene Aufgaben verallgemeinern. Neue Aufgaben erfordern erweitertes Training oder ein neues Modell. (In folgenden Teilen der Serie werden wir aber Anstrengungen dazu anschauen wie eine gewisse Generalisierung trotzdem zu bewerkstelligen sein könnte)
- Labelbasierte Klassifikation ist weniger flexibel als generative Ansätze. Viele Aufgaben lassen sich nicht rein diskriminierend lösen. Zum beispiel das Verfassen von Zusammenfngen etc.
Dies ist erst der Beginn eines Austauschs. Wenn Sie erfahren möchten, wie Parashift Sie auf Ihrem Weg zur Automatisierung unterstützen kann, zögern Sie nicht, uns zu kontaktieren.