Document Swarm Learning®: Autonome KI-Technologie die Massen-Trainingsdaten nutzt.
Parashifts wichtigste Innovation ist eine Reihe von Funktionen namens Document Swarm Learning® AI. Es handelt sich um eine Technologie, die systematisch Daten sammelt, Modelle für maschinelles Lernen neu trainiert und verbesserte Modelle automatisch auf der Plattform bereitstellt. Erfahren Sie mehr darüber, was Document Swarm Learning® ist.

Parallelisiertes Lernen
Paralleles Lernen mit verschiedenen Methoden führt zu einer besseren Extraktionsqualität.
Lernen vor Ort
Die Dokumenten-KI von Parashift trainiert auf Feldebene und kann das Training auf mehrere Dokumente verteilen.
Den Schwarm ausnutzen
Schwarmvorhersagen aus einem Netz von KI verbessern das Ergebnis von Vorhersageproblemen drastisch.
Unabhängige AI-Agenten
Unabhängige KI-Agenten, die auf eine bestimmte Aufgabe spezialisiert sind, erzielen eine hohe Leistung.
Ein radikal neuer Ansatz für die intelligente Dokumentenverarbeitung.
Die Vision von Parashift war es schon immer, eine generische Intelligent Document Processin API zu entwickeln, die es ermöglicht, dokumentenbasierte Prozesse in bestehenden Anwendungen mit so wenig Konfiguration, Schulung und Integration wie möglich zu automatisieren. Document Swarm Learning ist die Antwort auf die Frage, wie man in Zukunft 3.000 Dokumenttypen vortrainieren kann.
„Wir bauen viele neue Technologien auf, damit Sie als Kunde immer an der Spitze der Entwicklungen in der intelligenten Dokumentenverarbeitung stehen.“
Andre Bieler (Leiter AI Parashift)

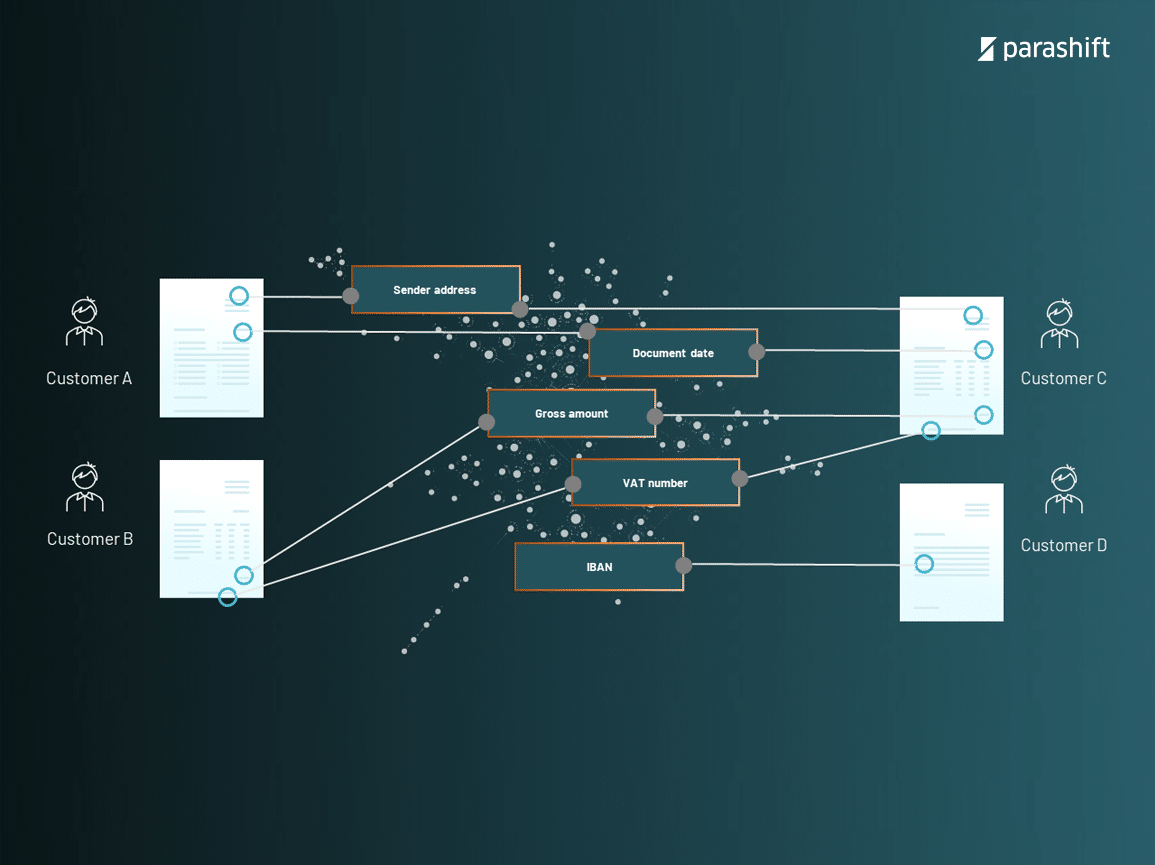

Die Parashift-Plattform sammelt Trainingsdaten aus allen Anwendungsfällen und Mietern, konvertiert diese Daten in ihr eigenes Trainingsdatenformat und nutzt das große kombinierte Datennetzwerk, um Tausende von Modellen automatisch zu trainieren.
Ein neuartiger Ansatz zur Lösung der Extraktion von Dokumentendaten.
Im Gegensatz zu herkömmlichen Systemen verknüpft Parashift Platform die Lernmodelle nicht mit bestimmten Dokumenttypen. Stattdessen unterteilt die Plattform die Modelle in Extraktionseinheiten. Extraktionseinheiten stellen einen strukturierten, normalisierten Wert dar, der gefunden werden soll. In einer Softwareanwendung kann dies z. B. ein Datenfeld sein.
Lernmodelle entkoppelt von Dokumenttypen.
Die bahnbrechende Methodik von Parashift wird unabhängig von der Extraktionsmethode selbst angewendet. Die Extraktionseinheiten sind von den Dokumenttypen getrennt und von den Lernmodellen entkoppelt. Dadurch können die Extraktionsmethoden auf eine neue Weise miteinander in Beziehung gesetzt werden.

Mehrere Modelle für dieselbe Feldeinheit.
Pro Extraktionseinheit können Lernmodelle und Extraktionsmechanismen in Konkurrenz zueinander gesetzt werden. Ein weiteres Modell bildet die Bewertung des jeweils besten Lernmodells und der besten Extraktionsmethode ab. Auf diese Weise ist es möglich, die Lernmodelle unabhängig vom Dokumententyp zu verbessern. Die Verbesserung führt dazu, dass für dieselben Extraktionseinheiten kein zusätzlicher Lernaufwand für den jeweiligen Mieter betrieben werden muss. Dieses Verfahren ermöglicht auch die einfache und zeitsparende Konfiguration neuer Dokumenttypen mit „vorgelernten“ Extraktionseinheiten.