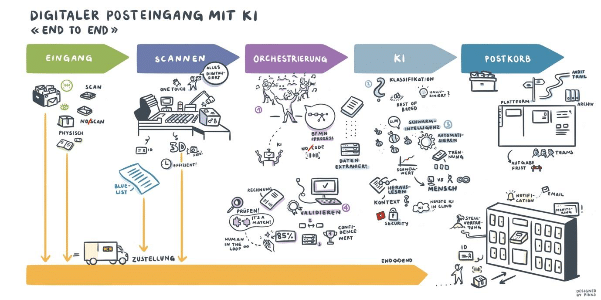
Wir bei Parashift fokussieren uns auf das Leveragen von pragmatischen state-of-the-art Machine Learning (ML) Technologien, um spezifische Probleme für unsere Kunden zu lösen. Das Problem, das dabei im Zentrum steht, ist die strukturierte Datenextraktion von Geschäftsdokumenten.
Gartner schätzt, dass heute mehr als 80% der Unternehmensdaten unstrukturiert sind. Das heisst, diese sind für Unternehmen in Form von Freitext in Emails und anderen schriftlichen Dokumenten verschlossen. So ist es denn auch nicht sonderlich erstaunlich, dass das autonome Klassifizieren und Daten Extrahieren von Dokumenten nach wie vor grosse Herausforderungen sind, die es zu meistern gilt. Wieso das so ist, hat diverse Hintergründe. Auf zwei grundlegende gehe ich hier kurz ein:
Mit Templates allein gehts nicht
Dokumente, selbst solche, die wir grundsätzlich als eher standardisiert bezeichnen würden wie beispielsweise Rechnungen, kommen immer wieder in einem anderen Layout beziehungsweise in einer anderen Struktur daher. Das heisst, dass eine einfache OCR (Optical Character Recognition) Maschine bei Abweichungen vom Normalfall schlicht keine Ahnung mehr hat, wo sie auf dem Dokument nach was suchen muss. Sie sehen, die Komplexität ist oftmals schon bei scheinbar banalen Dokumenten relativ hoch.
Ein pragmatischer Lösungsansatz für eine solche Problematik ist die Erstellung einer Vielzahl an statischen Templates, welche die Strukturunterschiede der jeweils verschiedenen Dokumente und Zusteller festhalten soll. Die Resultate dieses Vorgehens sind in der Regel gut. Doch je mehr Geschäftsverkehr und Stakeholder ein Unternehmen hat, desto schneller wird das zu einer ziemlichen Management-Challenge. Und die reine Anwendung erstellter Templates auf Formate, die die Maschine zuvor noch nie gesehen hat, ist aussichtslos.
Maschinen sind anfällig auf Noise
Eine weitere Herausforderung kommt von der Qualität der Dokumente aus, welche wir im Tagesgeschäftes antreffen können. Sind diese nicht wirklich sauber gedruckt oder qualitätsmässig schlecht fotografiert oder gescannt und ans Postfach weitergeleitet worden, werden solche Fälle für die OCR Maschine schnell problematisch. Denn bei der Interpretation der Input-Werte “sieht” sie oftmals zu viel Noise (Störungen) und kann folge dessen keine verwertbaren Daten mehr liefern.
Ein Schritt in Richtung autonomer Dokumentenverarbeitung
Diese und weitere Probleme haben wir spezifisch adressiert und entwickelten in diesem Prozess entsprechende Methoden, die es uns ermöglichen, einen grossen Schritt vorwärts in Richtung autonomer Dokumentenverarbeitung zu kommen. Diverse dieser Methoden haben wir daher auch beim Patentamt angemeldet.
Für die Verarbeitung der Dokumente haben wir beispielsweise einen mehrschichtigen Prozess aufgebaut, der je nach Qualität des Inputs schnell oder sehr schnell durchgeführt werden kann. Nehmen wir zur Veranschaulichung einmal an, dass eine Datei in der Pipeline ist, welche eine schlechte Qualität aufweist. Dieses Dokument wird aufgrund dessen zuerst von verschiedenen eigens entwickelten Enhancement Algorithmen bearbeitet und erst dann weitergegeben, wenn dessen Inhalte für die OCR Maschine gut erkennbar sind. Das Pre-Processing von solchen Dokumenten kann natürlich beliebig weiterentwickelt werden. Und so haben wir neben inkrementellen Verbesserungen auch diverse neue coole Features auf der Roadmap und werden diese im Verlauf des Jahres 2020 releasen. An einer Möglichkeit um Batch Verarbeitungen von grossen Stapeln unterschiedlicher, eingescannter Dokumente ohne Trennpapier vorzunehmen, arbeiten wir ebenfalls. Das System muss hier aber robust und schnell genug sein, um unterschiedliche Dokumenttypen erkennen und die einzelnen Seiten einander zuzuordnen zu können. Wenn wir damit live gehen können, ist noch unklar. Einmal machbar, werden wir damit aber den Automationsgrad der End-to-End Automation von jeglichen Dokument-lastigen Prozessen stark erhöhen können. So viel steht fest.
Das Problem mit den schier endlosen Templates lösen wird mit dem Parashift Learning Network. Durch dieses profitieren unsere Kunden von allen Standard Dokumenten und Learnings, die mit unserer Maschine verarbeitet beziehungsweise internalisiert wurden. Das heisst, je mehr Dokumente wir von einem bestimmten Typen in einer grösstmöglichen Variation verarbeitet haben, desto grösser ist die Wahrscheinlichkeit, dass der Dokumententyp in seiner Natur von der Maschine verstanden wurde und sie so die relevanten Daten eruieren und extrahieren kann. Folge dessen wird die Maschine immer besser und immer mehr Kunden werden aufgrund der überlegenen Qualität auf Parashift setzen wollen. Es handelt sich hier also um einen Reinforcement-Mechanismus.
Heute sind wir besonders auf deutschen Kreditorenrechnungen und Quittungen stark. Eine Validierung der Daten muss nur noch in Sonderfällen vorgenommen werden. Unser Engineering Team arbeitet aber parallel an 64 weiteren Standard Dokumenttypen wie beispielsweise Kreditkartenabrechnungen, Bankbelegen und Versicherungspolicen, welche anfangs 2020 live geschaltet werden. Auch bezüglich anderer Sprachen kann in absehbarer Zeit mit qualitativen Resultaten gerechnet werden. Denn wir haben bereits mehrere Kunden, wo wir Dokumente in Englisch, Französisch und Italienisch verarbeiten dürfen.
Da wir ferner unserer Standard Dokumente trotzdem auch auf die individuellen Bedürfnisse unserer Kunden eingehen wollen, entwickeln wir gerade eine Software, mit welcher auch nicht technisch affinen Mitarbeiterinnen und Mitarbeitern ermöglicht wird, in wenigen Stunden komplexe Dokumenttypen für die Maschine zu konfigurieren und mit einem Sample Set von 10 bis 1000 Belegen anzutrainieren. Die Learnings der Maschine auf diesen individuellen Dokumenten werden im Vergleich zu den Standard Dokumenttypen aber nicht mit dem Netzwerk geteilt. Die Anzahl der hier benötigten Trainingsbelege für eine solide Automationszuverlässigkeit ist stark abhängig von der Komplexität des Dokumenttyps. Konkret werden Kunden auf Basis der Standard Dokumenttypen aufbauen und zusätzliche zu extrahierende Felder definieren können. Das Interface zur Validierung, insofern diese die Kunden selbst übernehmen wollen, sowie die API werden dabei automatisch den neuen Konfigurationen angepasst. Die untenstehende Visualisierung verdeutlicht den Prozess Schritt für Schritt.
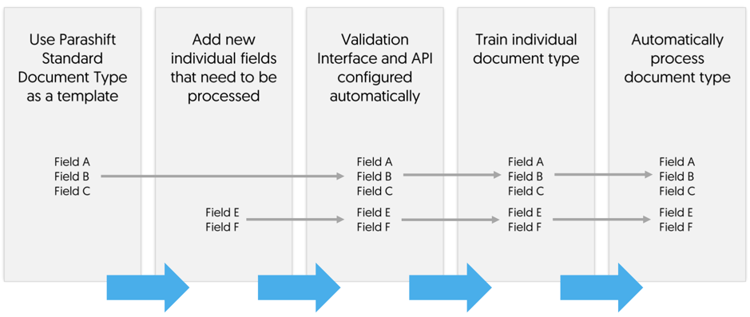
Bahnbrechend an dieser neuen Software ist, dass wir einen Prozess von mehreren Wochen oder gar Monaten auf nur einen Tag reduzieren werden können.
Ein Fundament für individuelle Weiterentwicklung
Eine weitere praktische Charakteristik unserer Lösung ist, dass wir durch die Architektur der Software Entwicklern ermöglichen, schnell weitere post-Extraktionsprozesse zu implementieren, die wiederum RPA Clean Up Prozesse ersetzen können. Ein Beispiel dazu ist die Implementation von KI-Lösungen, die mittels Natural Language Processing (NLP) die extrahierten Daten mit Stammdaten in anderen IT Systemen zur Verifikation abgleichen. Andere sind Software-Lösungen zur Betrugs Vorhersage und grundsätzlichen Anomalieerkennung.
Mit unserer API Lösung schaffen wir also eine essenzielle Basis für die Einführung beziehungsweise Weiterentwicklung von revolutionären Prozessen, die zum Wachstum von führenden Unternehmen einen grossen Beitrag leisten. Denn Prozessinnovationen wie Robotic Process Automation (RPA) sind nur so gut, wie die Daten, die ihnen als Grundlage zur Automation dienen. Was heute noch in Dokumenten, Bildern und anderen Medien verborgen ist, wird in absehbarer Zeit verfügbar gemacht werden können und ein nie dagewesenes Potenzial für die Neugestaltung von Organisationen und Prozessen bieten.