Machine Learning (ML), Computer Vision und Robotic Process Automation (RPA) sind einige der am meisten gehypten Wörter im Tech Space heutzutage. Warum auch nicht?! Denn der Einfluss, den die dahinterstehenden Technologien bereits heute in den verschiedensten Geschäftsbereichen haben, ist erheblich. Sie führen zu rationalisierten Unternehmensabläufen, Kostensenkungen, intelligenten Lösungen oder Weiterentwicklungen, schnelleren Entscheidungen und diversen weiteren Vorteilen.
Wie kann RPA für Unternehmen nützlich sein?
RPA ermöglicht es Unternehmen, so genannte „Roboter“ zu konfigurieren, die menschliche Handlungen und Arbeitsabläufe nachahmen können. Die Technologie hilft demnach Unternehmen, die alltäglichen Aufgaben und regelbasierten, statischen, sich wiederholenden Prozesse zu automatisieren. Dies hat mehrere offensichtliche Vorteile:
- Die automatisierten Systeme sind viel schneller und sparen dadurch Zeit und Geld
- Zeiteinsparungen ermöglichen es dem Management, diese freigesetzten Ressourcen alternativ für andere höherstehende Arbeiten, die Kreativität und andere menschliche Fähigkeiten bedingen, einzusetzen
- Prozesse sind weniger fehleranfällig als manuelle Arbeit
- RPA ist in der Regel leicht skalierbar und eignet sich daher für Organisationen, die mit vielen Daten- und Informations-basierten Prozessen zu tun haben
Diese Vorteile haben zu weit verbreitetem Einsatz und Popularität von RPA geführt. Genutzt werden die Systeme beispielsweise, um sich in Anwendungen einzuloggen, Dateien und Ordner zu verschieben, Daten zu kopieren und wieder zu einfügen, Berechnungen durchzuführen, Websites durchzustöbern und relevante Daten rauszuziehen sowie Textinhalte aus Dokumenten, PDFs, E-Mails und Formularen zu extrahieren. Neben diesen exemplarischen Use Cases gibt es aber etliche weitere Einsatzmöglichkeiten, wo RPA prädestiniert ist.
Optische Zeichenerkennung (Optical Character Recognition = OCR)
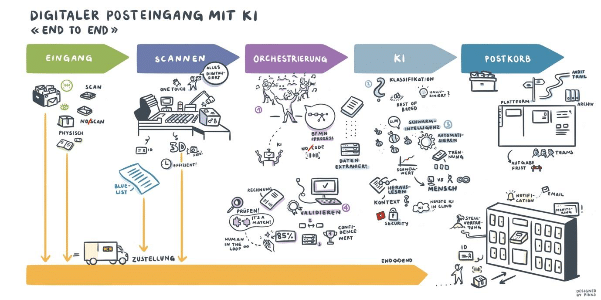
Es ist ziemlich offensichtlich, dass Dokumentenextraktion und RPA stark voneinander profitiert haben. Dies aufgrund dessen, da mit Hilfe von OCR relevante Informationen aus Dokumenten unterschiedlicher Art wie Rechnungen, Bilanzen, Rechtsdokumenten, Kontoauszügen, Steuererklärungen, usw., automatisiert extrahiert werden können. OCR Technologien verwenden dazu visuelle Techniken, um ein Bild auf Ränder, Schriftarten und Zeichen zu scannen. Durch den Gebrauch ergänzender Techniken wie zum Beispiel neuronale Netzen erkennt sie die Zeichen und verwendet darüber hinaus linguistische Konzepte der Natural Language Processing (NLP), um Wörter und Semantik zu erkennen. Für RPA relevant sind diese Technologien also, da dadurch weitere Arbeitsschritte in verschiedenen Prozesse ebenso teil- oder vollautomatisiert werden können. Und da Automation bei vielen Firmen Top of Mind ist, wird entsprechend viel in diese Richtung investiert, geforscht und gearbeitet.
Ein Beispiel zur Untermauerung der Relevanz: Stellen Sie sich einen Menschen vor, der versucht, diese kleinen Datenstücke aus Tausenden von Rechnungen zu lesen und sie in die Datenbank zu kopieren. Dies geschieht nicht nur sehr langsam und ist langweilig, sondern in der Regel auch ziemlich fehleranfällig. Dank den Möglichkeiten von OCR sind Aufgaben wie die Dateneingabe grösstenteils automatisiert und präziser geworden. Anstatt manuell in einem 100-seitigen Dokument nach einem bestimmten Text zu suchen, können diese Programme das Dokument innert Kürze scannen und den Inhalt im Handumdrehen abrufen beziehungsweise ausgeben. Zugegeben, nicht immer fehlerfrei.
OCR-Herausforderungen für RPA-Entwickler
Wie jede andere Technologie hat auch OCR seine Probleme und offenbart Anwendern eine gewisse Komplexität. Das häufigste Problem ist die fehlerhafte Zeichenerkennung, die auf mehrere Faktoren zurückzuführen sein kann:
- Schlechte Qualität des Scanners, was zu Flecken und ungleichmässigem Kontrast auf dem Dokument führt
- Wiederholtes Scannen eines bereits gescannten Dokuments
- Falsche Ausrichtung der Seiten im Dokument
- Präsenz von Wasserzeichen, Stempeln und handgeschriebenem Text auf dem Dokument
- Zerknitterte und/oder verblasste Dokumente
- Spezielle Textformate mit verschiedenen Blöcken und Umbrüchen
Wenn das Dokument oder der Scan eines der obigen Merkmale aufweist, können wir möglicherweise nicht den gewünschten Grad an Genauigkeit erreichen. Dies kann beispielsweise zu Fällen führen, in denen die OCR-Engine eine „5“ als „S“ oder den Buchstaben „O“ anstelle der Zahl „0“ erkennt. Bei Dokumenten, die tabellarische Daten enthalten wie Rechnungen und Bilanzen, wird es schwierig, die Grenzen der Spalten zu erkennen, was zu einer fehlerhaften Zuordnung der Daten führen kann.
Wie man sieht, haben solche Situationen negative Auswirkungen und sind Knackpunkte in der Architektur, Entwicklung und dem Betrieb von RPA Anwendungen. Wenn zum Beispiel ein Dezimalpunkt fehlt und $400,00 als $40000 gelesen wird, kann dies gravierende Folgen haben. Dies daher, da normalerweise diverse weitere Schritte auf den Resultaten der Dokumentenextraktion basieren und teilweise über längere Zeit – das wäre auf jeden Fall in einer Idealwelt so angedacht – menschliche Supervision fehlt. Eine Ungenauigkeit in diesem frühen Stadium kann daher eine ernsthafte Herausforderung für die nachgeschalteten Prozesse darstellen, die die eingelesenen Daten weiterverarbeiten. Hinzu kommt die Tatsache, dass es in einem Unternehmen Tausende oder gar Millionen solcher Dokumente gibt, die fortlaufend verarbeitet werden müssen. Fehler zu Beginn des Prozesses übertragen sich auf dem Weg zu den nachgeschalteten Prozessen und werden somit zu Fehlern im Dokumentenmanagement-System (DMS), ERP oder anderen führenden Systemen führen. In Kurzform: OCR-basierte RPA Anwendungen sind oftmals weniger Robust und mit dem Bedarf für menschliche Intervention konfrontiert, sprich, verlangsamt. Und dennoch ist es ein unabdingbarer Weg, weil so Daten von verschiedenen Medien kostengünstig in einem System erfasst werden können.
Wie können diese Herausforderungen überwunden werden?
Sie sehen, an dieser Stelle ist – zumindest heute noch – die menschliche Nachbearbeitung unerlässlich. Nun haben Sie die Möglichkeit, entweder selbst interne Prozesse zu entwickeln und einzuführen, damit Ihre Mitarbeitenden die extrahierten Metadaten Ihrer OCR auf Fehler überprüfen und Korrekturen (in diesem Kontext auch Annotation gennant) vornehmen können oder Sie suchen nach einem dedizierten Anbieter, der in diesen Belangen aufgrund der Spezialisierung wesentlich effizienter unterwegs ist und entscheiden sich somit, diese Leistungen stattdessen einzukaufen.
Mit Parashift kriegen Sie all dies aus einem Haus. Das heisst, einerseits eine marktführende OCR Software aber zugleich auch effiziente und beliebig skalierbare Annotation der Extraktionsergebnisse. Neben dem dadurch möglichen Effizienzgewinn ist also ein weiterer Vorteil, dass Sie abgesehen von stets korrekten Daten auch eine kontinuierliche Verbesserung der Extraktionssoftware realisieren können, für welche Sie im Vergleich zu herkömmlichen OCR Anbietern keine hochpreisigen Investitionen tätigen und Projekte planen müssen. Dabei beschränkt sich die Verbesserung der Parashift OCR übrigens nicht nur auf die Genauigkeit, sondern auch auf die Unterstützung verschiedener Dokumenttypen. Konkret ist Parashift bestrebt, allerlei gängigen Geschäftsdokumente des Alltages so zu standardisieren, dass Sie beispielsweise einfach einen Vertrag hochladen können und Sie unmittelbar die wichtigsten Daten daraus in perfekter Qualität zurück erhalten. Konfiguration und Training sollen dazu nicht mehr notwendig sein. Um mehr darüber zu erfahren, lesen Sie doch diesen Beitrag hier.
Was die Implementierung, Optimierung und Skalierbarkeit unserer Dokumentenextraktions-Lösung betrifft, so bietet die Cloud-basierte OCR Software zahlreiche Vorteile. Denn die offene und erweiterbare Plattform ermöglicht den sofortigen Zugriff auf Funktionalitäten und Learnings, die auf einer extrem grossen Anzahl von Dokumenten basieren und bedingen daher keine kostspieligen und langwierigen Projekte, bis Sie mit dem Normalbetrieb starten können. Zudem ist die Software aufgrund simplen und gut dokumentierten APIs einfach in allerlei Business Software zu integrieren. So sind Legacy-System-Projekte vergleichsweise immense Geld verschlingende Unterfangen und erst noch nicht wirklich zukunftsfähig.
Zusammenfassend lässt sich sagen, dass OCR Technologien bereits einen langen Weg zurückgelegt haben, um zunehmend verlässlicher in der Lage zu sein, Informationen korrekt aus noch so unstrukturierten Dokumenten zu extrahieren. Doch auch wenn diese Lösungen dato heute leistungsstark sind und die Kosten um ein Vielfaches reduzieren können, bleiben gewisse Herausforderungen bezüglich Genauigkeit bestehen. In dieser Hinsicht ist ein effizientes menschliches Eingreifen sinnvoll und auch noch notwendig, sodass Fehler vermeiden und die Fähigkeiten der Extraktionsmaschine nachhaltig verbessert werden können.
Wie erwähnt, kombinieren wir bei Parashift genau diese beiden Dimensionen: Top-notch Machine Learning Technologien und menschliche Nachbearbeitung. Dies, um eine flexible und effiziente Lösung zu schaffen, die jeder Herausforderung der Dokumentenextraktion gewachsen ist und stets ausgezeichnete Daten liefert. Etwas, das Stand heute sonst kein anderer OCR Provider liefern kann. Probieren Sie es selbst aus!