In der sich schnell entwickelnden digitalen Welt sind unabhängige Softwareanbieter (ISVs) ständig auf der Suche nach innovativen Lösungen, die sie ihren Kunden anbieten können. Die Parashift Platform ist ein Leuchtturm auf dieser Suche, denn sie bietet ein KI-basierte-OCR-System, das die Dokumentenverarbeitungslandschaft für die Kunden von ISVs grundlegend verändert. In diesem Artikel erfahren Sie, wie Parashift ISVs in die Lage versetzt, eine überragende Lösung für die Dokumentenverarbeitung zu liefern und dabei die Leistungsfähigkeit fortschrittlicher OCR- und KI-Technologien zu nutzen.
Verbesserung der Kunden-Dokumentenverarbeitung mit der AI OCR-Technologie von Parashift
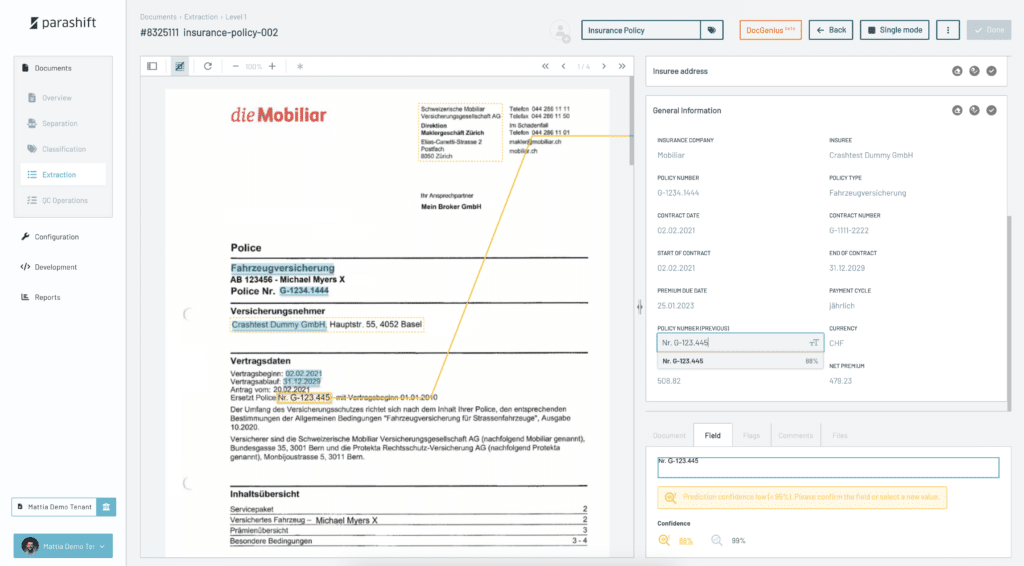
Stellen Sie sich das Szenario eines ISV vor, der im Versicherungssektor tätig ist und dessen Kunden mit der Bearbeitung von Schadensfällen überfordert sind. Diese Versicherungsunternehmen kämpfen oft mit der Genauigkeit und Geschwindigkeit der Dokumentenverarbeitung, eine Herausforderung, die sich direkt auf ihre Effizienz und Kundenzufriedenheit auswirkt. Hier setzt der ISV an, der mit der fortschrittlichen KI-OCR-Technologie von Parashift ausgestattet ist, um die Abläufe seiner Kunden zu revolutionieren. Durch die Integration der Lösung von Parashift ermöglicht der ISV diesen Versicherungsunternehmen eine schnellere und genauere Bearbeitung von Schadensfällen. Die Technologie von Parashift ist in der Lage, verschiedene Dokumententypen zu verstehen, von detaillierten Versicherungsformularen bis hin zu komplexen Verträgen, und gewährleistet so eine hohe Genauigkeit und Effizienz bei der Dokumentenverarbeitung. Diese Verbesserung steigert nicht nur das Wertversprechen des ISV, sondern erhöht auch die operativen Möglichkeiten seiner Versicherungskunden erheblich.
Rationalisierung der Abläufe durch intelligente Dokumentenverarbeitung und Skalierbarkeit
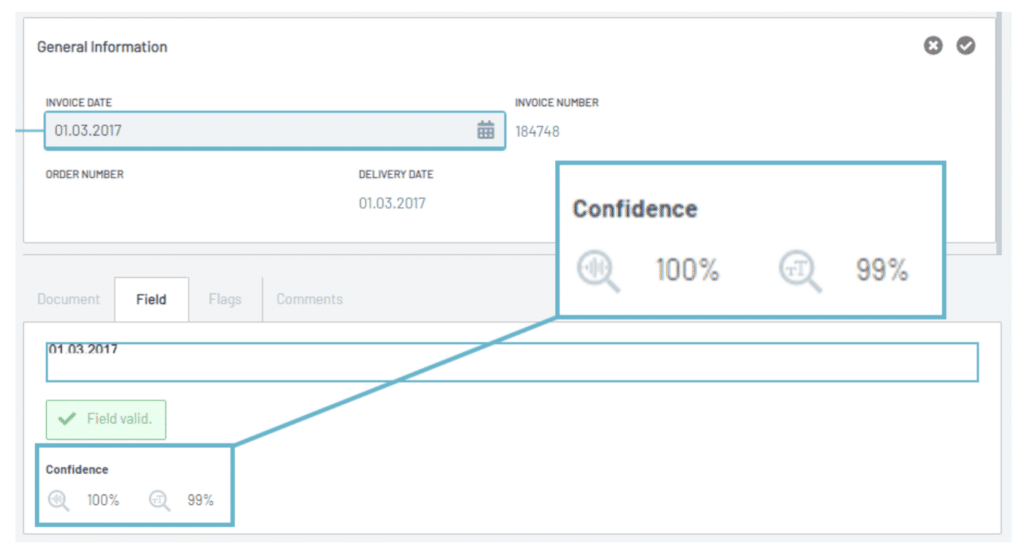
Stellen Sie sich eine Anwaltskanzlei vor, die eine Vielzahl von Akten in verschiedenen Formaten und Sprachen bearbeitet. Die intelligente Dokumentenverarbeitung (IDP) von Parashift kombiniert OCR mit maschinellem Lernen und KI und verändert damit das Datenmanagement der Kanzlei. Die Software erfasst nicht nur die Daten genau, sondern versteht sie auch im Kontext, was für die Verwaltung verschiedener juristischer Dokumente unerlässlich ist. Wenn die Kanzlei wächst, sorgt die skalierbare Lösung von Parashift dafür, dass steigende Dokumentenmengen verarbeitet werden können, ohne dass die Verarbeitungsgeschwindigkeit oder die Genauigkeit beeinträchtigt werden.
Nahtlose Integration und zukunftssichere Lösungen für ISV-Kunden
Die Plattform von Parashift ist so konzipiert, dass sie sich problemlos in eine Vielzahl von Systemen integrieren lässt, egal ob es sich um ERP-, CRM- oder kundenspezifische Software handelt. Ein Beispiel für diese nahtlose Integration ist der Fall einer Einzelhandelskette, die die OCR-API von Parashift integriert hat, um ihr Bestandsverwaltungssystem zu verbessern, was zu einer verbesserten Workflow-Effizienz führte.
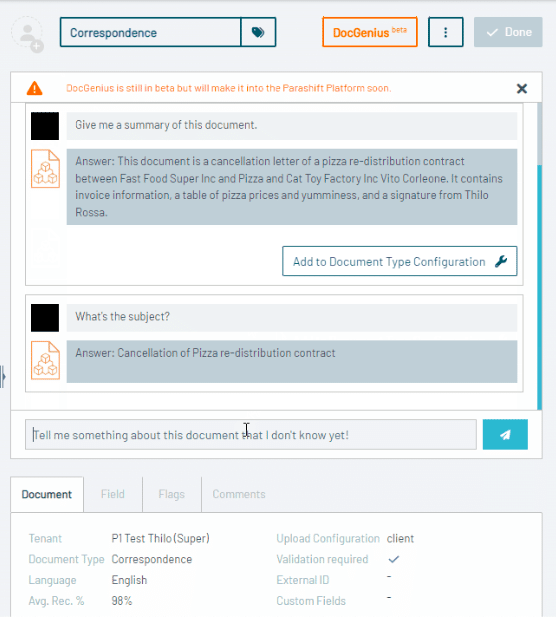
Darüber hinaus können ISV-Kunden durch die Integration fortschrittlicher Sprachmodelle wie GPT OCR sicher sein, dass sie der Technologiekurve immer einen Schritt voraus sind und von den neuesten Fortschritten in der Dokumentenverarbeitungstechnologie profitieren.
Einhaltung von Sicherheits- und Compliance-Standards
Sicherheit und Compliance sind von größter Bedeutung, insbesondere für ISVs, die Kunden in regulierten Branchen wie dem Gesundheits- oder Finanzwesen bedienen. Die Verpflichtung von Parashift zur Einhaltung strenger Datensicherheits- und Compliance-Standards stellt sicher, dass alle verarbeiteten Dokumente den branchenspezifischen Vorschriften entsprechen, was das Vertrauen der ISV-Kunden stärkt.

Schlussfolgerung
Parashift bietet nicht nur ein Tool an, sondern ist das Tor zu einer neuen Ära des Dokumentenmanagements. Für ISVs, die ihren Kunden eine erstklassige Dokumentenmanagementlösung anbieten wollen, ist Parashift der perfekte Partner. Mit unserer Kombination aus fortschrittlichen OCR- und KI-Technologien, skalierbaren Lösungen, nahtloser Integration und unerschütterlichem Engagement für Sicherheit ermöglichen wir ISV-Kunden eine effiziente Verwaltung ihrer Dokumentenverarbeitung.
Sind Sie bereit, Ihr Dokumentenmanagement zu revolutionieren? Setzen Sie sich noch heute mit Parashift in Verbindung, um herauszufinden, wie unsere Plattform Ihr Angebot erweitern und Ihnen einen Vorsprung im Bereich des Dokumentenmanagements verschaffen kann.