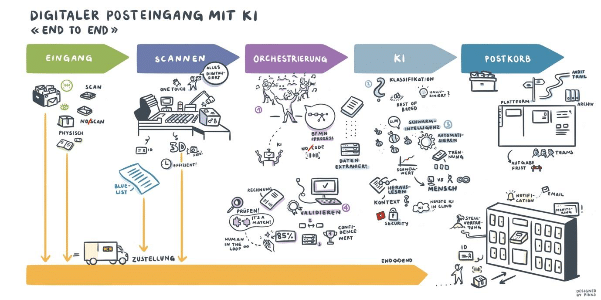
Nachdem wir im letzten Artikel die Unterschiede wie auch Vor- und Nachteile von dezentralem und zentralem Scanning angeschaut haben, widmen wir uns nun hier dem gutem Scanning. Denn es fliessen viele verschiedene Faktoren in jedes gescannte Dokument ein, die eine Auswirkung auf alle nachgelagerten Prozesse haben. Angefangen beim Dateiformat über die Kompression bis hin zur Auflösung. Deshalb ist eine Vielzahl von Kombinationen zur Umsetzung möglich, wobei sich manche für gewisse Aufgaben besser eignen als andere. Wenn nun ein Mensch einige Daten auf einem gescannten Dokument ablesen will, so muss das Dokument gewisse Anforderungen erfüllen. Einigermassen gut lesbar beispielsweise. Folglich verhält es sich sehr ähnlich, wenn wir Dokumente mit einer OCR Software auslesen wollen. Sprich, auch hier sind zwangsläufig einige Standards zu erfüllen. Ansonsten sind die Ergebnisse der automatisierten Datenextraktion tendenziell klar schlechter.
Farbmodi
Typischerweise werden die drei Modi Bitonal, Graustufen und Farbe für das Scanning verwendet. Für Parashift ist es nicht wichtig, ob das Dokument farbig oder schwarz-weiss gescannt wurde, die Algorithmen sind in beiden Fällen funktional. Es liegt also bei Ihnen, für welchen Farbmodus Sie sich entscheiden.
Dateiformat
Wie Sie sicherlich wissen, gibt eine Vielzahl an verschiedenen Dateiformaten, die für das Scanning von Dokumenten verwendet werden können. Einige der gängigsten sind PDF, PDF/A, TIFF, JPG und PNG.
Auch in diesem Aspekt spielt es für die Parashift Plattform keine grosse Rolle, mit welchem Format Sie arbeiten wollen. Wichtig ist, dass Sie ein Dateiformat wählen, dass für Sie in Ihrem Unternehmenskontext passt. Konkret heisst das, das Dateiformat soll sich eignen, langfristig damit arbeiten zu können und es soll auch für Ihre Archivzwecke geeignet sein.
Kompression
Die Kompression ist ein wichtiger Gesichtspunkt, da bei falscher Kompression entweder Daten verloren gehen können oder aber zu viel Speicherplatz aufgewendet wird. Wird gar nicht komprimiert, dann ist der Scan zwar besonders genau, aber die Datei wird zu gross sein für Archivierungszwecke.
Verarbeiten Sie Dokumente mit uns, dürfen die an unsere API gesendeten Dokumente ruhig bereits komprimiert sein. Eine Grösse von 40 – 50 Kilobyte pro gescannter bitonaler (schwarz-weiss) A4 Seite ist optimal. Grössere Dokumente sind natürlich auch kein Problem, wobei dies für die Archivierung eher suboptimal ist.
Auflösung
Die Scanauflösung dürfte der wohl kritischste Punkt beim erfolgreichen Dokumentenscan sein. Sie wird typischerweise mit der Anzahl dots per inch – kurz DPI – gemessen. Wie der Name schon sagt, drückt diese Zahl aus, wie viele Punkte sich auf einem Zoll befinden. Diese Zahl gilt es nicht zu verwechseln mit pixel per inch, also PPI.
Als Faustregel ist: Eine Auflösung mit 300 DPI ist ausreichend für einen Scan. Wenn nur mit 200 DPI oder weniger gescannt wird, ist zwar die Datei kleiner, aber dementsprechend sind im Scan auch weniger Ausgangsdaten vorhanden. Bei Parashift und anderen OCR Anbietern kann es folglich bei niedriger Auflösung zu Problemen in der Erkennung und Extraktion kommen. Ist die Auflösung zu niedrig, ist beispielsweise die Wahrscheinlichkeit, dass der Buchstabe B als die Zahl 8 gelesen wird oder die Zahl 1 als klein L wesentlich höher. Um dieses Problem zu illustrieren, zeigen die nachfolgenden Grafiken einen Ausschnitt aus einem gescannten A4 Dokument, wobei sie sich lediglich durch die Auflösung unterscheiden. Die Dokumente sind nach aufsteigender Scanauflösung geordnet.
Es ist offensichtlich, dass das erste Bild viel schwieriger zum Einlesen sein dürfte und daher auch die Fehleranfälligkeit höher ist. Die Zahl 1 kann hier missverständlich als klein L gelesen werden. Bei 300 DPI sieht das hingegen anders aus. Bei dieser Auflösung wird der Scan fehlerfrei erfolgen können.
Die Schriftgrösse spielt übrigens bei der Auflösung ebenfalls eine Rolle. Wenn auf einem A4 ein Text mit Schriftgrösse 5 mit 300 dpi eingescannt wird, limitiert dies die Performance von OCR-Lösungen relativ bedeutend.
Folgen einer niedrigen Auflösung sind also zum einen eine niedrigere Qualität aber auch eine Geschwindigkeitsverminderung bei der Zeichenerkennung der Engine. Da die Zeichen auf dem Dokument teilweise nicht eindeutig sind, müssen mehrere Erkennungsvarianten verarbeitet werden, was verständlicherweise mehr Zeit benötigt. Um eine optimale Auflösung zu erhalten, sollte daher wenn auch immer möglich einerseits die DPI Anzahl bei 300 liegen und andererseits die Schriftgrössen nicht zu klein sein.