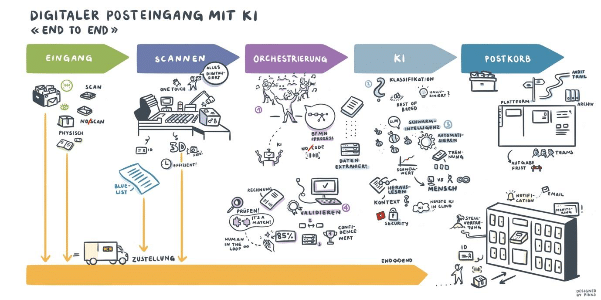
Programme zur automatischen Verarbeitung von Dokumenten kommen immer dann zum Einsatz, wenn Dokumente automatisch klassifiziert und Daten extrahiert werden sollen. Das heisst, es muss bestimmt werden um was für eine Art von Dokument es sich handelt (Vertrag, Korrespondenz, Rechnung, …) und welche wichtigen Daten aus dem Dokument extrahiert werden müssen (Kundenname, Nummern, Beträge, …).
In jedem Fall sollen sie den Anwendern manuellen Aufwand abnehmen. Wie gut diese Systeme funktionieren und wie viel Aufwand sie den Endanwendern dann effektiv abnehmen können, wird oft durch Extraktionsraten ermittelt. Diese Raten geben prozentual an, in wie vielen Fällen automatisiert und ohne menschlichen Eingriff Daten korrekt aus dem Text des Dokumentes ausgelesen werden konnten.
Entsprechend wird diesen Extraktionsraten eine sehr hohe Wichtigkeit zugesprochen. Sie sind daher auch Thema in fast jedem Verkaufsgespräch für eine neue “OCR Software”. (OCR bezeichnet im Allgemeinen nur die Erkennung sämtlichen maschinengeschriebenen Textes auf einem Dokument, steht aber oft als Synonym für Software zur Klassifizierung von Dokumenten und Datenextraktion aus diesem OCR Volltext.)
Extraktionsraten im Verkaufsgespräch, mehr Bauchgefühl als fundiertes Wissen
Im Sales lernt man nun schnell diese Frage gekonnt aus dem Weg zu räumen, da man durch die Beantwortung nur verlieren kann. Entweder die Konkurrenz hat eine höhere, magische, aus der Luft gegriffene Zahl versprochen und man verliert, ohne dass das je geprüft wurde. Oder im späteren Produktivbetrieb wird die genannte Zahl zum Bumerang mit dem Satz: “Sie haben aber damals versprochen, das System würde XX% Daten von alleine erkennen!” (Meistens ist dieses Problem leider dem Verkäufer egal, da dies dann der Techniker oder Support Mitarbeiter ausbaden muss :-))
Fakt ist, je nach zu verarbeitenden Dokumenten und Beleggut können die Quoten höher oder niedriger ausfallen. Dies hängt im Wesentlichen von folgenden Faktoren ab:
- Liegen die Dokumente in einer guten Qualität vor (Scan, Foto, gescannte Kopie eines Fotos mit schlechter Auflösung bei zu geringer Belichtung, …)?
- Hat die Plattform bereits viele ähnliche Dokumente verarbeitet?
- Ist die Konfiguration auf bestimmte Sonderfälle vorbereitet?
- Müssen verschiedene Schriftzeichensätze verarbeitet werden (lateinisch, griechisch, kyrillisch, …)?
- Welche Art von Daten müssen extrahiert werden (einfache Kopfdaten, komplexe Sätze oder tabellarische Positionsdaten)?
Den Use Case in den Vordergrund stellen
Was die Frage nach den Extraktionsraten aber oft ausser Acht lässt, ist der tatsächliche Use Case für den derartige Software eingeführt wird. Wie zu Beginn gesagt, geht es im Endeffekt immer darum eine Tätigkeit zu automatisieren. Die Frage ist nur: Warum soll diese Tätigkeit automatisiert werden?
Meist läuft es auf die zwei folgenden Szenarien hinaus:
1. Dem Endanwender soll die Erfassung von Daten schnellstmöglich vereinfacht werden, damit er mit dem Ergebnis sofort weiterarbeiten kann. Dies ist zum Beispiel der Fall, wenn Dokumente über eine App an eine Versicherung oder Bank geschickt werden. Kerndaten sollen dabei extrahiert und dem Benutzer angezeigt werden, damit sie um ggf. weitere Informationen ergänzt werden können. Wurden Daten nicht sauber erkannt, muss ein Benutzer diese manuell vervollständigen.
2. Dem Endanwender soll die langwierige und mühsame Erfassung von Daten abgenommen werden, um mit dem Ergebnis zeitnah weiter arbeiten zu können. Dieser Fall unterscheidet sich dadurch, dass es nicht darum geht schnellstmöglich ein Resultat zu bekommen, sondern darum, besonders gute, saubere Daten zu erhalten, da die manuelle Erfassung ansonsten viel Zeit in Anspruch nehmen würde. Ob dies nun in 2 Sekunden oder 3 Stunden automatisch passiert ist zweitrangig. Beispiele hierfür sind unter anderem die Erfassung langer, komplexer Rechnungen mit vielen Positionsdaten, welche für einen Abgleich gegen die Bestellung oder für das Reporting benötigt werden.
Im Fall 1 führen falsche Extraktionsergebnisse zu unzufriedenen Anwendern. Im Beispiel mit der Versicherung führt dies schlimmstenfalls dazu, dass die Benutzer die App nicht nutzen und die Rechnungen lieber weiterhin auf Papier einschicken und somit Aufwand bei der Versicherung statt dem Endanwender generieren.
Trotzdem sollte hier das Augenmerk weniger auf ein System mit sehr guten Extraktionsraten gelegt werden, sondern lieber auf ein System mit guten Extraktionsraten sowie einer permanenten Verbessrung hin zu perfekten Extraktionsraten. Es nützt nichts, wenn das System nicht lernt und so dieselben Fehler immer und immer wieder macht. Dies führt ebenfalls dazu, dass Benutzer nicht zufrieden sind. Wenn die Benutzer aber merken, dass die Erkennung immer besser wird, sind sie auch gewillt das Produkt weiter zu verwenden, da sie wissen, dass daran gearbeitet wird.
Im zweiten Fall führen falsche Extraktionsergebnisse zu hohen manuellen Aufwänden im internen Prozess. Am Beispiel der Positionsdaten kann bereits eine falsch ausgelesene Position dazu führen, dass alle Positionen kontrolliert werden müssen, um den Fehler zu finden. Hier steht also eher der Ansatz ganz oder gar nicht. Lieber gleich auf einen Service setzen, der vollvalidierte, also korrekt geprüfte Daten verspricht, als auf eine Software die gute aber unter mitunter unvollständige oder inkorrekte Ergebnisse liefert.
Langfristige Perfektion gegenüber kurzfristiger, teurer Mittelmässigkeit
In jedem Fall wird oft zu wenig nach dem tatsächlichen Ergebnis, welches erreicht werden soll, gefragt und zu viel Wert auf perfekte Extraktionsraten gelegt. Auch wenn der Titel etwas anderes behauptet sind diese natürlich wichtig, niemand will ein System welches gerade einmal 50% der Daten korrekt erkennt. Aber ein System, welches vollvalidierte Daten ausliefern kann und das sich zum Ziel gesetzt hat, künftig ohne menschliche Interaktion perfekte Extraktionsraten zu liefern ist mittelfristig mehr wert als ein System, das durch hohe Initialaufwände und extremste Anpassungen auf einem bestimmten Dokumenttyp gute Ergebnisse liefert.
Das nächste Mal, wenn Sie über Extraktionsraten sprechen, überlegen Sie sich daher genau, wem diese überhaupt nutzen und welches Problem Sie eigentlich mit der Automatisierung der Dokumentverarbeitung beheben wollen.
Wenn Sie wissen wollen wie Parashift Ihnen bereits heute perfekte Metadaten liefern kann, und wie dies mit unserer Vision der vollautonomen Dokumentverarbeitung zusammenhängt, dann können Sie über den folgenden Button direkt Kontakt mit mir aufnehmen.