Der Markt für Optical Character Recognition (OCR) beziehungsweise Document Capture Software wird bis 2027 voraussichtlich ein Volumen von 12,6 Milliarden USD erreichen. Das bei einem jährlichen Wachstum von ca. 10%. Die steigende Nachfrage nach Softwarelösungen zur Dokumentenextraktion ist hauptsächlich auf Compliance-Initiativen, die Digitalisierung des Dokumentenmanagements und die Absicht, die Betriebskosten zu optimieren, zurückzuführen. Aber auch wegen der zunehmend mobilen Arbeitskräfte und der oft damit verbundenen Notwendigkeit der Dokumentenverarbeitung über mobile Geräte. Obwohl OCR von einer Vielzahl von Menschen als gelöstes Problem betrachtet wird, gibt es hier noch viele Herausforderungen zu lösen. Die Handschrifterkennung (engl. Handwritten Text Recognition oder kurz HTR) ist eine davon. Die hohe Varianz der Handschriftstile und die teils schlechte Qualität des handgeschriebenen Textes im Vergleich zum maschinell gedruckten Text, stellen erhebliche Hindernisse bei der Umwandlung in maschinenlesbare Textformate dar. Nichtsdestotrotz handelt es sich um ein entscheidendes Problem, das für mehrere Branchen wie zum Beispiel das Gesundheitswesen, Versicherungen und Banken von Relevanz ist und wir bei Parashift unbedingt lösen wollen. Entsprechend sind unsere Forschungs- und Entwicklungsaktivitäten in vollem Gange.

Source: ResearchGate
Relativ neue Fortschritte im Bereich des Deep Learnings wie beispielsweise das Aufkommen von Transformer-Architekturen haben unsere Lernkurve in der handschriftlichen Texterkennung ziemlich stark beschleunigt. In der Branche spricht man dabei übrigens gewöhnlich von Intelligent Character Recognition (ICR). Dies ist daher, da die Algorithmen, die für ICR benötigt werden, mehr „Intelligenz“ benötigen als die von generischer OCR.
In diesem Artikel erfahren Sie mehr über den Task der Erkennung von handgeschriebenem Text, die Komplikationen und wie wir sie mit verschiedenen Techniken des Deep Learnings lösen können.
Hauptherausforderungen von HTR
- Enorme Variabilität und Mehrdeutigkeit der Schriften von Mensch zu Mensch
- Inkonsistenz im Schreibstil
- Schlechte Qualität des Quelldokuments aufgrund von Verschlechterung im Laufe der Zeit
- Oftmals ist der Text nicht streng geradlinig gehalten
- Die kursive Handschrift macht die Trennung und Erkennung von Zeichen noch schwieriger
- Text in Handschrift kann unterschiedliche Neigungen haben
- Das Sammeln eines qualitativ hochwertigen Datensatzes mit Labels ist relativ teuer
Anwendungsfälle
Healthcare und Pharma
Einer der relevanteren Pain Points im Gesundheitswesen und in der pharmazeutischen Industrie ist die Digitalisierung von Patientenrezepten. Beispielsweise verarbeitet Roche täglich Unmengen von medizinischen PDFs. Auch die Patientenregistrierung und andere Cases zur Digitalisierung von Formularen erfordern eine zuverlässige Lösung, die handschriftliche Texte erkennen und extrahieren kann. Durch das Implementieren von automatischer Handschrifterkennung in Geschäftsprozessen können Gesundheits- und Pharmaunternehmen also ihre Prozesseffizienz und die Kundenzufriedenheit erheblich verbessern.
Insurance
Eine grosse Versicherungsgesellschaft kann schnell einmal ein paar Millionen Dokumente an einem einzigen Tag erhalten. Eine Verzögerung bei der Bearbeitung von beispielsweise Schadensfällen hat demnach einen signifikanten Impact. Da die Anspruchsdokumente, welche unterschiedliche Handschriftenstile enthalten können, regelmässig rein manuell bearbeitet werden, hat die Automatisierung der Verarbeitung hier einen bedeutenden Bottleneck, der mit HTR adressiert werden kann.
Banking
Ich weiss, es ist vielleicht schwer zu glauben, aber Leute stellen tatsächlich immer noch regelmässig Schecks aus und deshalb spielen diese Art von Dokumenten bei den meisten bargeldlosen Transaktionen immer noch eine relativ grosse Rolle. In einigen Ländern natürlich mehr als in anderen. In vielen Entwicklungsländern erfordert das derzeitige Verfahren der Scheckbearbeitung, dass ein Bankmitarbeiter die auf einem Scheck vorhandenen Informationen prüft und manuell einträgt. Da diese Schecks in den meisten Fällen für die Verarbeitung zentralisiert werden, ist es durchaus üblich, dass Tag für Tag eine grosse Anzahl solcher Schecks bearbeitet werden muss. Mit anderen Worten, auch hier könnte ein leistungsstarkes Handschrifterkennungssystem eine beträchtliche Anzahl Stunden menschlicher Arbeit einsparen und zu so hohen Kosteneinsparungen führen.

Online-Bibliotheken
Ein weiterer Bereich, in dem HTR ins Spiel kommt, sind die Online-Bibliotheken. Denn hier werden grosse Mengen historischer Schriften digitalisiert und damit für Menschen auf der ganzen Welt online zugänglich gemacht. Wegen der riesigen Datenmengen sind solche Bemühungen jedoch nur dann wirklich nützlich, wenn man den Text auf diesen Scans identifizieren, sie indexieren und abfragen kann.

Methods
Im Grossen und Ganzen lassen sich die Methoden zur Handschrifterkennung in zwei verschiedene Typen einteilen:

Bei der Online-Handschrifterkennung arbeiten wir in der Regel mit einem digitalen Stift und haben dadurch Zugriff auf die Strichinformationen wie etwa die Position des Stifts, während geschrieben wird. Das obige Bild illustriert dies sehr gut und sollte auch verdeutlichen, dass wir für Online-Schriften in der Regel über eine gute Menge an Daten verfügen, was es wesentlich einfacher macht, Zeichen mit höherer Genauigkeit zu klassifizieren.
Bei den Offline-Methoden hingegen wird der Text nach der Niederschrift und nur auf Basis dieser Grundlage klassifiziert. Daher haben wir bedeutend weniger Merkmale, die wir für Vorhersagen verwenden können. Noch schlimmer ist, dass wir möglicherweise auch mit Hintergrund-Noise umgehen können müssen, welche vom Papier ausgehen.
Wenn es in der realen Welt nicht so schwierig wäre, den Ansatz mit dem digitalen Stift richtig zu skalieren, wäre die also Aufgabe der Erkennung von handgeschriebenem Text nicht mehr so schwierig. Da es aber nun mal so ist, wie es ist, müssen wir Lösungen finden, die uns helfen, die Informationen, die wir von nicht-digitalen Stiften erhalten, möglichst effizient zu nutzen. Deshalb werden wir uns jetzt mit verschiedenen Techniken befassen, die sich als vielversprechend erweisen, das Problem der Erkennung von offline geschriebenem Text zu lösen.
Einige der Techniken
Die ersten Ansätze zur Handschrifterkennung waren Machine Learning Methoden wie zum Beispiel die bekannten Hidden-Markov-Modelle (HMM), Support Vector Machines und dergleichen. Diese Ansätze konzentrierten sich auf die Merkmalsextraktion nach einer anfänglichen Vorverarbeitung des Textes. Bei diesen Merkmalen kann es sich zum Beispiel um Schleifen, Wendepunkte, Verhältnisse irgendeiner Art und andere Aspekte eines einzelnen Zeichens handeln. Nach der Extraktion werden die Merkmale einem Klassifikator wie dem HMM zugeführt. Dies mit dem Ziel, möglichst gute Ergebnisse zu erhalten. Solche Ansätze sind jedoch stark auf manuelle Arbeit für die Merkmalsextraktion angewiesen und somit nicht skalierbar sowie hinsichtlich der Lernfähigkeit ziemlich begrenzt. Infolgedessen ist die Leistung dieser Art von Machine Learning-Modellen eher logischerweise stark begrenzt.
Aber es gibt gute Nachrichten: Wie eingangs erwähnt, hat Deep Learning ein völlig neues Spektrum an Möglichkeiten eröffnet, die bestehenden Probleme anzugehen und enorme Verbesserungen in der Genauigkeit hinzukriegen. Im Folgenden werde ich auf einige der relevanteren Forschungsarbeiten auf diesem Gebiet eingehen.
Multi-dimensional Recurrent Neural Networks
Recurrent Neural Networks (RNN) oder Long Short-Term Memory (LSTM), bei welchen es sich um eine spezielle RNN-Architektur handelt, sind dafür bekannt, dass sie mit sequentiellen Daten umgehen können, um zeitliche Muster zu identifizieren und Ergebnisse zu generieren. Zumindest die gängigsten Konfigurationen dieser Art von Architekturen. Dennoch gibt es eine bedeutende Einschränkung: Sie können nur 1D-Daten verarbeiten. Daher können diese Architekturen auch nicht direkt auf Bilddaten angewendet werden. Um dieses Problem zu lösen, schlugen die Autoren des Papiers „CITlab ARGUS for Arabic Handwriting“ eine mehrdimensionale RNN/LSTM-Struktur vor. Eine solche ist hier visualisiert.
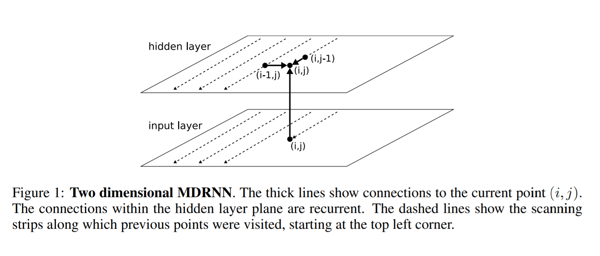
Was ist also der Unterschied zwischen einem traditionellen RNN und dem vorgeschlagenen mehrdimensionalen RNN… Im Allgemeinen ist es bei RNNs so, dass die verborgene Schicht i den Zustand von einer vorhergehenden verborgenen Schicht in der Zeit i-1 erhält. Bei mehrdimensionalen RNNs, nehmen wir das Beispiel einer zweidimensionalen RNN-Struktur, erhält die verborgene Schicht (i, j) Zustände von mehreren vorhergehenden verborgenen Schichten, nämlich (i-1, j) und (i, j-1). Daher erfassen solche Architekturen den Kontext sowohl von der Höhe als auch von der Breite her in einem Bild, was für ein klares Verständnis der lokalen Region von entscheidender Bedeutung ist. Sie können dies weiter ausbauen, um auch Informationen aus zukünftigen Schichten zu erhalten. Dies ist also in der Art und Weise ziemlich ähnlich wie Bidirektionale Long Short-Term Memory Netzwerke (BI-LSTM) Informationen von t-1 und t+1 erhalten. Um auf unsere hypothetische zweidimensionale RNN-Struktur zurückzukommen: Hier wären wir nun in der Lage, Informationen ebenso in beiden Richtungen zu empfangen. Also beispielsweise in (i-1, j), (i, j-1), (i+1, j), (i, j+1). So können wir wie beim BI-LSTM Kontext in allen Richtungen zu erfassen.
Was Sie in der Abbildung unten sehen können, ist im Grunde die gesamte mehrdimensionale RNN-Struktur. Was wir also tun, ist einfach den RNN-Block durch einen LTSM-Block zu ersetzen. Der Input des Netzwerks wird in Blöcke der Größe 3×4 unterteilt, der in die mehrdimensionalen RNN-Schichten bzw. die hierarchische Struktur des Netzwerks aus mehrdimensionalen RNN-Schichten eingespeist wird, gefolgt von Feed-Forward-Schichten im Tandem. Feed-Forward-Schichten sind klassische künstliche neuronale Netze. Der endgültige Output wird in einen 1D-Vektor umgewandelt und an eine CTC-Funktion (Connectionist Temporal Classification) weitergeleitet, um ein Output zu erzeugen.
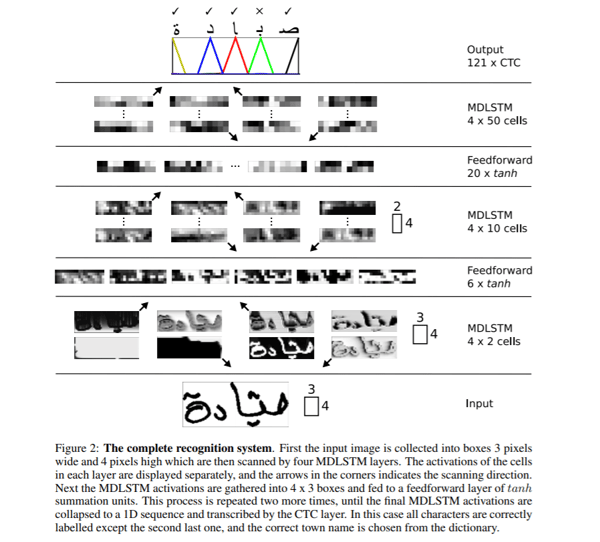
CTC ist ein Algorithmus, der zur Bewältigung von Aufgaben wie Spracherkennung und Handschrifterkennung verwendet wird. In beiden Fällen handelt es sich um Aufgaben, bei denen nur die Eingabedaten und die Transkription des Ouputs zur Verfügung stehen und keine Angaben zur Ausrichtung gemacht werden. Sprich, wie eine bestimmte Region in einem Audio-File für Sprache oder eine bestimmte Region in Bildern für Handschrift auf ein bestimmtes Zeichen ausgerichtet ist. Das Problem dabei ist, dass einfache Heuristiken wie beispielsweise jedem Zeichen den gleichen Bereich zu geben, nicht funktionieren, da der Platz, den jedes Zeichen einnimmt, bei den Handschriftarten sehr unterschiedlich sein kann. Eine gute Quelle für weitere Informationen über die Funktionsweise von CTC finden Sie hier.
Wenn wir die Ausgabe eines CTC unter Verwendung einfacher Heuristiken der höchsten Wahrscheinlichkeit für jede Position dekodieren, erhalten wir möglicherweise Ergebnisse, die in realen Fällen nicht viel Sinn ergeben. Deshalb müssen wir eine andere Art von Decoder verwenden, der vielversprechender ist, um unsere Ergebnisse zu verbessern. Um ein besseres Verständnis für die Entscheidungsfindung zu erhalten, betrachten wir die verschiedenen Arten der Dekodierung, die es gibt:
- Die Best-Path-Dekodierung ist die generische Dekodierung, die wir bisher implizit diskutiert haben. Bei diesem Typ nehmen wir an jeder Position den Ouput des Modells und finden einfach das Ergebnis mit der höchsten Wahrscheinlichkeit.
- Bei der Beam Search-Dekodierung schlägt die Beam Search vor, mehrere Ausgabepfade mit den höchsten Wahrscheinlichkeiten beizubehalten und dadurch die Kette mit neuen Outputs zu erweitern, während Pfade mit niedrigeren Wahrscheinlichkeiten fallen gelassen werden, um die Beam-Grösse konstant zu halten.
- Die Beam Search liefert in der Regel genauere Ergebnisse als die Grid Search. Aber es gibt noch Raum, um wirklich aussagekräftige Ergebnisse zu erlangen. Eine Möglichkeit eine höhere Leistung anzustreben, besteht darin, neben der Beam Search ein Sprachmodell zu verwenden, bei dem sowohl Wahrscheinlichkeiten aus dem Modell als auch dem Sprachmodell (das z.B. Zeichenfolgen nach Wahrscheinlichkeiten bewertet) verwendet werden, um die Endergebnisse zu erzeugen.
Weitere Einzelheiten zur Erzeugung genauer Dekodierungsergebnisse können in diesem Artikel nachgelesen werden.
Encoder-Decoder und Attention Networks
Seq2Seq-Modelle (Sequenz zu Sequenz) mit Encoder-Decoder-Netzwerken sind in letzter Zeit ziemlich populär geworden. Auch zur Spracherkennung oder maschinellen Übersetzung. In Folge dessen wurden sie dann ebenso zur Lösung des Anwendungsfalles HTR eingesetzt, wobei hier zusätzlich Aufmerksamkeitsmechanismen implementiert werden. Schauen wir uns einige der jüngsten Forschungen auf diesem Gebiet näher an.
Scan, Attend and Read
Im Paper „Scan, Attend and Read: End-to-End Handwritten Paragraph Recognition with MDLSTM Attention“ schlagen die Autoren die Verwendung eines aufmerksamkeitsbasierten Modells für die End-to-End-Mehrzeilen-Handschrifterkennung vor. Der Hauptbeitrag dieses Papers besteht in der automatischen Transkription von Text, ohne dass dieser als Vorverarbeitungsschritt in Zeilen segmentiert werden muss. So können sie stattdessen einfach eine ganze Seite scannen und direkt Ergebnisse liefern.
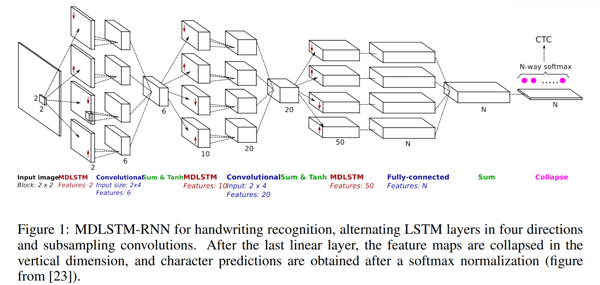
Scan, Attend and Read (SAR) verwendet eine auf dem mehrdimensionalenLong Short-Term Memory (MDLSTM) basierende Architektur, ähnlich der, die wir bereits zuvor diskutiert haben, mit einem kleinen Unterschied in der letzten Schicht. Nach der letzten linearen Schicht, also dem letzten Summenblock in der oben stehenden Abbildung, werden die Feature-Maps in der vertikalen Dimension kollabiert und eine Softmax-Funktion angewendet, um den Output zu erhalten.
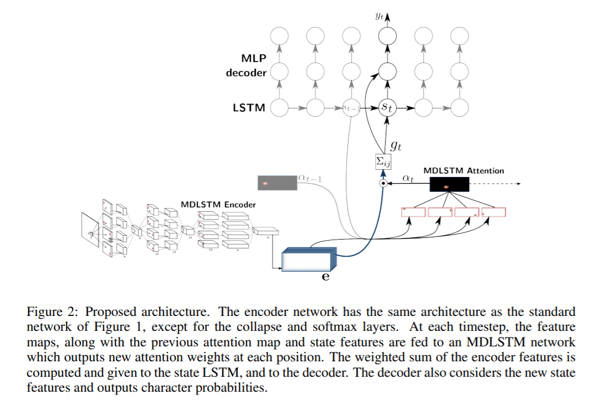
Die SAR-Architektur besteht aus einer MDLSTM-Architektur, die als Merkmalsextraktor fungiert. Das abschliessende kollabierende Modul mit einem implementierten Softmax-Output und CTC-Verlust wird durch ein Attention-Modul und einen LSTM-Decoder ersetzt. Das angewandte Aufmerksamkeitsmodell ist eine hybride Kombination aus inhaltsbasierter Aufmerksamkeit und ortsbasierter Aufmerksamkeit. Was dies bedeutet, können Sie in dem Papier lesen, das wir als nächstes diskutieren werden. Im Allgemeinen erlauben Aufmerksamkeitsmechanismen einem Modell, den Zustand zu einem früheren Zeitpunkt direkt zu betrachten und daraus Schlussfolgerungen zu ziehen, so dass es sich bei jedem Dekodierungsschritt auf die relevantesten kodierten Merkmale konzentrieren kann. Die Decoder-LSTM-Module nehmen hingegen den vorherigen Zustand, die vorherige Attention-Map und die Codiermerkmale, um ein Ausgabezeichen und den Zustandsvektor für die nächste Vorhersage zu erzeugen.
Convolve, Attend and Spell
Das Paper „Convolve, Attend and Spell: An Attention-based Sequence-to-Sequence Model for Handwritten Word Recognition“ schlägt ein aufmerksamkeitsbasiertes Sequenz-zu-Sequenz-Modell vor. Die vorgeschlagene Architektur besteht aus drei Hauptteilen: Einem Encoder, bestehend aus einem Convolutional Neural Net (CNN) und einem bidirektionalen GRU, einem Aufmerksamkeitsmechanismus, der sich auf die entsprechenden Merkmale konzentriert und einem Decoder, der aus einem eindirektionalen GRU besteht, der in der Lage ist, das entsprechende Wort Zeichen für Zeichen zu buchstabieren.
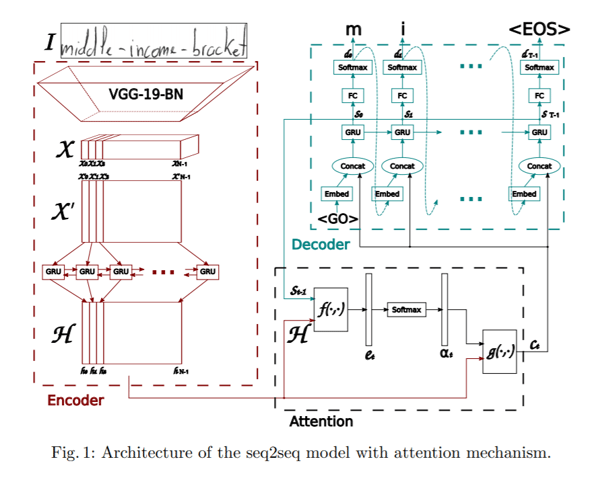
Der Encoder verwendet ein CNN, um visuelle Low-Level Merkmale zu extrahieren. Insbesondere wird eine vortrainierte VGG-19-BN-Architektur (im Grunde ein 19 Schichten tiefes Netzwerk, Batch-normalisiert) als Merkmalsextraktor verwendet. Das Eingabebild wird dabei in eine Merkmal-Repräsentation X konvertiert, die dann in X‘ umgeformt wird, indem alle Kanäle spaltenweise aufgeteilt und kombiniert werden, um die sequentiellen Informationen zu erhalten. X‘ wird weiter in H konvertiert, indem eine bidirektionale GRU verwendet wird. GRU ist ein neuronales Netzwerk, das in seiner Natur dem LSTM ähnelt und zeitliche Informationen erfassen kann.
Zuzüglich wird ein Aufmerksamkeitsmodell angewendet, während der Output des Decoders vorhergesagt wird, wobei ein RNN in jedem Zeitschritt ein Zeichen decodiert und somit das ganze Wort buchstabiert. Die Autoren diskutieren zwei verschiedene Arten von Aufmerksamkeitsmechanismen, die sie untersucht haben.
- Inhaltliche Aufmerksamkeit: Die Idee hinter dieser Methodik besteht darin, die Ähnlichkeit zwischen dem aktuellen verborgenen Zustand des Decoders und der Feature-Map vom Encoder zu finden. Wir können die am stärksten korrelierten Merkmalsvektoren in der Merkmalskarte des Encoders finden, die zur Vorhersage des aktuellen Zeichens im aktuellen Zeitschritt verwendet werden können. Eine intuitivere Art und Weise, die Funktionsweise von Aufmerksamkeitsmechanismen zu verstehen, finden Sie hier.
- Ortsbezogene Aufmerksamkeit: Der Hauptnachteil von ortsbezogenen Mechanismen ist die implizite Annahme, dass die Ortsinformation in die Ausgabe des Encoders eingebettet ist. Andernfalls gäbe es keine Möglichkeit, zwischen Zeichenausgaben zu unterscheiden, die vom Decoder wiederholt werden. Aber schauen wir uns ein Beispiel an, um die Dinge klarer zu machen. Nehmen wir an, wir haben das Wort Parashift, in dem das Zeichen a zweimal wiederholt wird. Ohne Ortsangaben kann der Decoder sie nicht als getrennte Zeichen vorhersagen. Um dieses Problem zu lösen, wird das aktuelle Zeichen und seine Ausrichtung vorhergesagt, indem sowohl der Output des Encoders als auch die vorherige Ausrichtung verwendet werden. Wenn Sie erfahren, wie die Methodik im Detail funktioniert, können Sie hier weiterlesen.
Der Decoder ist ein einseitig gerichteter, mehrschichtiger GRU. Zu jedem Zeitschritt t empfängt er Input vom vorhergehenden Zeitschritt und den Kontextvektor vom Aufmerksamkeitsmodul. Multinomiale Dekodierung und Label-Glättung werden im Training untersucht, um die Generalisierungsfähigkeit zu verbessern.
Transformer Modelle
Encoder-Decoder-Netzwerke haben sich bei der Handschrifterkennung erstaunlich gut bewährt. Dennoch weisen diese Art von Netzwerken aufgrund der beteiligten LSTM-Schichten einen erheblichen Engpass im Trainingsprozess auf. Denn aufgrund diesen können die Trainings nicht parallel laufen. Vor nicht allzu langer Zeit kamen jedoch Transformer Modelle auf, welche sich als sehr vielversprechend erwiesen und LSTM-Strukturen bei der Lösung einiger sprachbezogener Aufgaben ersetzt. Es stellt sich daher die Frage, wie wir diese für unseren Task der Handschrifterkennung einsetzen können.
Pay Attention to What You Read
Im Paper „Pay Attention to What You Read: Non-recurrent Handwritten Text-Line Recognition“ stellen die Autoren einen Non-Recurrent Ansatz vor, indem sie stattdessen eine Transformer-basierte Architektur und Multi-Headed Self-Attention-Schichten sowohl in der visuellen als auch in der inhaltlichen Phase verwenden. Dadurch können sie sowohl die Zeichenerkennung als auch die sprachlichen Abhängigkeiten der zu entschlüsselnden Zeichenfolgen erlernen. Da das Sprachwissen in das Modell selbst eingebettet ist, ist kein zusätzlicher Nachbearbeitungsschritt mit einem Sprachmodell erforderlich. Mit anderen Worten, es ist kein Vokabular notwendig, um Outputs vorhersagen zu können. Um dies zu erreichen, erfolgt die Textkodierung auf Zeichen- und nicht auf Wortebene. Da die Transformer-Architektur ein parallelisiertes Training für jede Region oder jedes Zeichen ermöglicht, ist der Trainingsprozess viel einfacher.
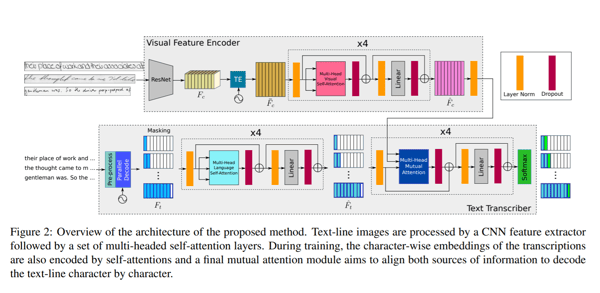
Die im Paper vorgeschlagene Netzwerkarchitektur besteht aus zwei Hauptkomponenten. Ein visueller Encoder, der relevante Merkmale extrahiert und Muti-Headed Visual Self-Attention auf verschiedene Zeichenpositionen anwendet sowie ein Texttranskribierer, der Texteingaben entgegennimmt, den Text kodiert, Muti-Headed Language Self-Attention und Mutations-Aufmerksamkeit auf sowohl visuelle als auch auf inhaltliche Merkmale anwendet.
Visual Encoder
Die Autoren verwenden das ResNet50 als eine Rückgrat Convolutional-Architektur, um die Merkmale zu extrahieren (in der Abbildung oben visualisiert). Die dreidimensionale Feature Repräsentation von ResNet50 wird an ein Temporal Encoding (TE)-Modul übergeben, das sich unter Beibehaltung der gleichen Breite und damit der Form von (f x h, b) zu 2D umformt. Diese wird in eine vollständig verbundene Schicht eingespeist, um die Form auf (f, w) zu reduzieren und in der Ausgabe Fc‘ resuliert, die als eine w-lange Sequenz von visuellen Vektoren gesehen werden kann. Zusätzlich wird zu Fc‘ eine Positionskodierung TE hinzugefügt, um die Positionsinformation zu erhalten. Die Ausgabe wird durch eine vollständig verbundene Schicht geleitet, um die endgültige Feature Repräsentation mit der Form (f , w) zu erhalten. Der endgültige Output wird durch ein Multi-Headed Attention-Modul mit 8 Köpfen geleitet, das eine visuell reichhaltige Feature-Map produziert. Um mehr über Transformer-Modelle zu erfahren, klicken Sie hier.
Texttranskribierer
Der zweite Teil der vorgeschlagenen Methodik ist eine Texttranskription. Dort wird der Text durch einen Encoder geleitet, der Embeddings auf Zeichenebene erzeugt. Diese Embeddings werden mit einem TE-Modul mit der zeitlichen Lage kombiniert, ähnlich wie im visuellen Encoder. Die Werte werden dann an ein Multi-Head Language Self-Attention-Modul weitergeleitet, das wiederum dem im visuellen Encoder verwendeten Modul ähnelt. Die Textmerkmale, die entlang der visuellen Merkmale vom visuellen Encoder generiert werden, werden an ein Modul für Mutation-Attention weitergeleitet, dessen einzige Aufgabe darin besteht, die gelernten Merkmale sowohl aus den Bildern als auch aus den Texteingaben auszurichten und zu kombinieren. Letztlich wird der Output durch eine Softmax-Funktion geleitet.
Handwriting Text Generation
Kommen wir wieder auf eine allgemeinere Ebene zurück und schauen uns die handschriftliche Texterzeugung an. Wie Sie sich vielleicht denken können, geht es hier um die Generierung von synthetischem handgeschriebenem Text oder – in anderen Worten – um die Erweiterung vorhandener Datensätze. Um sinnvolle Datenerweiterungen machen zu können, können wir uns auf Generative Adversarial Networks stützen.
ScrabbleGAN
ScrabbleGAN ist eine vorgestellte Methode, die einen Semi-Supervised Ansatz verfolgt, um handgeschriebene Textbilder zu synthetisieren, die sowohl im Stil als auch im Wortschatz unterschiedlich sind. Der Ansatz stützt sich auf ein neuartiges generatives Modell, das Bilder unterschiedlicher Länge erzeugen kann. Der Generator kann auch den resultierenden Textstil manipulieren, wodurch wir entscheiden können, ob der Text beispielsweise kursiv sein soll oder wie dick beziehungsweise dünn der Strich ist.
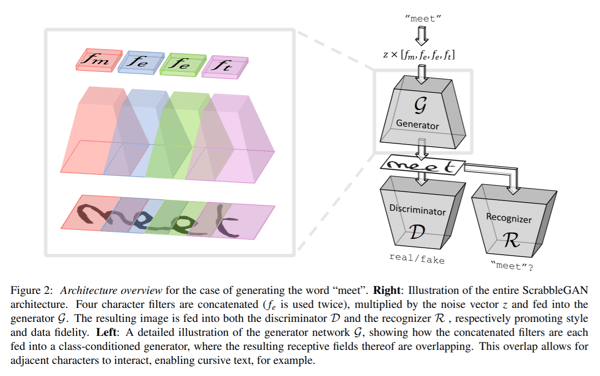
Die Architektur besteht aus einem vollständig auf BigGAN basierenden Convolutional-Generator. Für jedes Zeichen in der Eingabe wird ein entsprechender Filter aus einer Filterbank ausgewählt bevor alle Werte werden miteinander verkettet und dann mit einem Noise-Vektor z multipliziert werden. Wie in der oben stehenden Abbildung veranschaulicht, überlappen sich die für jedes einzelne Zeichen erzeugten Bereiche, was die Erzeugung von zusammenhängendem rekursivem Text erleichtert und die Flexibilität verschiedener Zeichengrössen ermöglicht. Zum Beispiel nimmt „m“ ziemlich viel Platz ein, während die „e“s nicht so viel Platz einnehmen. Um den gleichen Stil für das gesamte Wort oder auch den Satz beizubehalten, wird der Noise-Vektor z für alle Zeichen konstant gehalten.
Um zu klassifizieren, ob der generierte Stil eines Bildes gefälscht oder echt ist, wird ein Convolutional-Diskriminator implementiert, der auf einer BigGAN-Architektur basiert. Da sich der Diskriminator nicht auf Annotationen auf Zeichenebene angewiesen ist, basiert er nicht auf einem klassenbedingten GAN. Dies hat den Vorteil, dass keine beschrifteten Daten benötigt werden. Das heisst, dass auch nicht gelabelte Daten aus nicht bekannten Korpora zum Training des Diskriminators verwendet werden können. Zusammen mit dem Diskriminator wird ein Texterkenner R trainiert, um zu klassifizieren, ob der erzeugte Text echt ist oder ob es sich um Kauderwelsch handelt. Der Erkenner basiert auf einer Convolutional Recurrent Neural Network (CRNN)-Architektur. Der im Output von R erzeugte Text, wird dann mit dem an den Generator gegebenen Eingabetext verglichen und eine entsprechende Strafe zu einer Verlustfunktion hinzugefügt.
Einige der von ScrabbleGAN erzeugten Ausgaben sehen Sie hier:

Fazit
Wir haben in den letzten Jahren viele fundamentale Durchbrüche erlebt und doch ist HTR trotz all dieser Fortschritte bei den zugrunde liegenden Technologien noch lange kein gelöstes Problem. Angesichts der jüngsten Trends wie schnell wir vorankommen, könnte sich dies jedoch relativ bald ändern. Und nur um das auch erwähnt zu haben… Schon heute können wir Unternehmen Mehrwert stiftende Technologien zur Verfügung stellen, die den manuellen Aufwand in diesem Zusammenhang erheblich reduzieren.
Wenn Sie neugierig geworden sind und mehr über die Funktionalitäten von Parashift in dieser Hinsicht erfahren wollen, zögern Sie nicht, uns zu kontaktieren. Wir freuen uns, Ihnen eine detailliertere Einführung in das zu geben, was unsere Extraktions-Engine leisten kann.