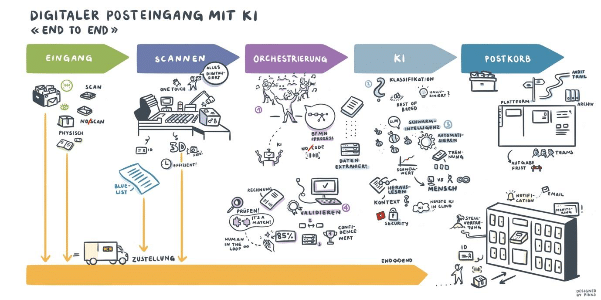
Dokumente spielen in der digitalen Transformation eine viel grössere Rolle, als uns lieb ist. Zahlreiche Studien zeigen, dass im überwiegenden Teil digitaler Prozesse an mindestens einer Stelle mindestens ein Dokument eingebunden ist. Fast immer sind diese Dokumente weder richtig digitalisiert, noch automatisiert. Das muss sich ändern.
Handbremse für die digitale Transformation
Dieser Umstand bremst digitale Prozesse erheblich aus und verhindert damit in vielen Fällen eine zügige digitale Transformation einzelner Geschäftsbereiche. Ich erlebe das täglich in den Diskussionen mit Entscheidungsträgern, die damit betraut sind, die digitale Transformation für ihr Unternehmen weiterzubringen.
Dokumente auslesen, das ist doch schon lange gelöst?
Man könnte nun meinen, dass das Auslesen von Dokumenten doch schon längst gelöst ist.
Doch obwohl wir seit mehr als 30 Jahren Dokumente elektronisch erfassen und auslesen, ist es das in der Praxis ganz offensichtlich noch nicht so. Zumindest nicht so, wie es sich für das Jahr 2021 gehört. Noch immer sind wir nicht am Punkt angelangt, wo x-beliebige Dokumente ganz einfach ausgelesen werden können. Das liegt daran, dass die heutigen Lösungen so aufgesetzt sind, dass sie vor allem Dokumententypen mit hohem Volumen verarbeiten können. Und dies auch nur dann, wenn ein Setup- und/oder Konfigurationsprojekt den individuellen Case aufgesetzt hat. Einen solchen hochvolumigen Dokumententypen nennen wir einen Dokumententypen, der in grosser Zahl im Unternehmen vorkommt. Typische Beispiele sind Lieferscheine, Rechnungen oder auch Bestellbestätigungen.
Für diese Dokumententypen gibt es seit langem bewährte Lösungen. Diese werden oft in mehrmonatigen Projekten als klassische Software verkauft und implementiert. Die dabei verwendeten Konfigurationen sind in der Regel starr und bedürfen, wenn sie angepasst werden müssen, wiederum eines Change Requests.
Das funktioniert daher gut, weil die schiere Menge der verarbeiteten Dokumente eine hohe Einsparung ermöglicht. Diese hohe Einsparungen wiederum erlaubt es den Unternehmen, auch hohe Investitionen in solche Systeme vorzunehmen.
Der Eisberg
Sehen wir uns das totale Volumen der Dokumente in einer Unternehmung an, bemerken wir rasch, dass diese hochvolumigen Dokumententypen in der Regel nur 20% des gesamten Dokumentenvolumens der Organisation repräsentiert.
Der Löwenanteil, rund 80% aller Dokumente, ist in kleinvolumige Dokumententypen aufgegliedert. Da mit bestehenden Systemen der Aufwand zum Einrichten der Dokumententypen aber grosso modo derselbe ist und das Volumen, wie die Bezeichnung ja schon sagt, eben klein ist, fehlt diesen Dokumententypen das Einsparungspotential, welches die Anfangsinvestitionen rechtfertigen würde.
Ergo werden diese kleinvolumigen Dokumententypen in aller Regel nicht digitalisiert und damit 80% der Dokumente analog und manuell verarbeitet.
Unternehmen haben heute diesbezüglich die Wahl zwischen zwei schlechten Optionen: Entweder sie investieren Unsummen, um eine nahtlose Digitalisierung zu ermöglichen (was sich defacto nicht rechnet) oder aber sie setzen weiterhin auf die manuelle Verarbeitung, was dazu führt, dass die digitalen Prozesse eben nur so halb digital sind.
Das ist so, weil die Technologie die Intelligent Document Processing universell macht, schlicht noch nicht Realität ist. Wir sprechen in dem Zusammenhang von der «technologischen Wasserlinie»: 20% des Dokumentenvolumens ist für die Digitalisierung sichtbar. Die restlichen 80% verbleiben unter der «technologischen Wasserlinie» verborgen. Das ist im Kern, was wir das Dokument-Eisberg-Problem nennen.
Universal Intelligent Document Processing
«Intelligent Document Processing» (IDP) ist ein relativ neuer Begriff – die Disziplin per se ist es mitnichten.
Zwar haben neue Technologien wie Machine Learning oder Deep Learning und ganz erheblich auch die viel günstigeren Rechenkapazitäten dafür gesorgt, dass schnell bessere Resultate erzielt werden können, doch so denke ich, stehen wir ganz am Anfang einer Entwicklung, die für alle im Bereich der digitalen Transformation immer wichtiger wird.
«Aus vielen Gesprächen mit Digitalisierungsverantwortlichen der letzten Jahre kenne ich die Frustration, die langsam einsickert, sobald man aus den digitalen Visionen digitale Realitäten machen will.»
Denn irgendwas ist immer. Und öfter als nicht sind es Dokumente, die in digitalisierten Prozessen eine Rolle spielen. Dass wir als ganze Digitalisierungs-Industrie das «Dokumenten- Eisberg-Problem» angehen, ist von übergreifender Bedeutung für die Digitalisierung. Denn Dokumente sind, entgegen dem vorherrschenden Narrativ, alles andere als am Verschwinden. Das Dokumentenvolumen nimmt laufend zu und allen Unkenrufen zum Trotz ist auch keine Trendwende absehbar. Das Einzige was in der Tat abnimmt, sind auf Papier gedruckte Dokumente.
Intelligent Document Processing (IDP) muss zur “Commodity” werden. Es muss universell werden. So einfach ist das.
Ein unglaubliches komplexes Problem
Ich habe die letzten 4 Jahre meines Lebens damit verbracht, mit meinem Team mich der Lösung dieses Problems zu widmen. Im Zentrum unserer Vision steht eine API, an welche die ganze Industrie zum Auslesen und Strukturieren der Dokumentendaten Dokumente senden kann und ohne Setup, ohne manuelles Eingreifen strukturierte Datenströme konsumieren kann. Für sprichwörtlich jedes Dokument auf dem Planeten. Da sind wir noch nicht, aber wir sehen einen klaren, wenn auch vergleichsweise weiten Pfad zu diesem Punkt. Unser heutiges Produkt wird von hunderten Kunden genutzt und bringt viel Wert in deren Prozesse – von unschätzbarem Wert ist, dass es die Grundlage für diesen Weg zur universellen Intelligent Document Processing API legt.
Was ich darüber gelernt habe, ist, dass diese Challenge massiv unterschätzt wird. Es ist eine Sache, ein System zu bauen, das einen Dokumententyp oder die Dokumententypen einer Branche abdecken kann. Eine möglichst universelle API zu bauen, ist um Grössenordnungen schwieriger. Und multipliziert sich mit jeder weiteren Dimension wie Sprache, geografische Abdeckung, etc. Wir beschäftigen uns sozusagen mit der Senkung der «technologischen Wasserlinie» – auf das immer mehr des Eisbergs für die Digitalisierung sichtbar wird.
Wie wir das bei die Parashift IDP Platform angehen, warum wir uns als Tech-Infrastruktur-Company verstehen und warum wir massiv vom «Data-Network-Effekt» profitieren, erläutere ich gerne in einem anderen Artikel.
Das Potential für die Digitalisierung ist schlicht riesig
Je näher wir universellem Intelligent Document Processing (IDP) kommen, desto klarer wird sich das unglaubliche Potential dieser Technologie im Business-Kontext zeigen. Sie werden automatisierte Businessprozesse realisieren können, die Sie sich heute noch gar nicht vorstellen können.
Denn es wird nicht nur möglich sein, die Kosten und Durchlaufzeiten durch die Reduktion von manueller Arbeit drastisch zu senken. Es werden eben neue Möglichkeiten entstehen, die wir noch gar nicht kennen.
Dass die ganze Menschheit jeden Tag so viel Zeit aufwendet, um Daten von Dokumenten abzulesen und manuell in Systeme einzugeben, ist schlichtweg verrückt. Wir akzeptieren das nur, weil wir keine Alternativen haben. Es ist Zeit das zu ändern. Stück für Stück. Dokumententyp für Dokumententyp.
Folgen Sie uns auf LinkedIn, um die neuesten IDP-Nachrichten zu erhalten.