Die effiziente Verarbeitung von Dokumenten ist für praktisch jedes Unternehmen aus jeder Branche von hoher Wichtigkeit, die Daten daraus essenziell für den Geschäftsablauf. In den letzten Jahren haben die Technologien, mit denen Dokumente verarbeitet werden, rasante Fortschritte gemacht. Angesichts der Prognose von IDC, die weltweite Datenmenge wachse bis 2025 auf 175 ZB an (wovon über 80 % unstrukturiert sind), werden auch weiterhin Technologiefortschritte notwendig sein, um die Dokumentenverarbeitung voranzutreiben.
In diesem Artikel gehen wir darauf ein:
- was der Status quo der Dokumentenverarbeitung ist,
- welches die aufkommenden Technologien sind,
- wie die Zukunft aussehen könnte und
- welche Herausforderungen es gibt und wie Parashift diese löst.
Der Status quo der Dokumentenverarbeitung

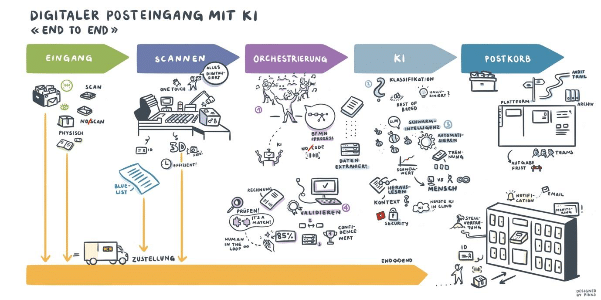
Die Dokumentenverarbeitung umfasst die automatisierte Bearbeitung elektronischer wie auch physischer Dokumente. Diese werden dabei in ein maschinenlesbares Format umgewandelt, so dass sie leichter zu analysieren, zu suchen und zu speichern sind. Auch wenn die Fortschritte der Technologien (dazu kommen wir gleich noch detaillierter) rasant sind, bleiben die Herausforderungen von Unternehmen in verschiedenen Branchen gleichwohl gross.
Zu den wichtigsten Teilen der Dokumentenverarbeitung gehören:
Klassifizierung: Die Klassifizierung ermöglicht die Kategorisierung der Dokumente auf Grundlage ihres Inhalts. So wird beispielsweise zwischen Bestellungen, Grundbuchauszügen, Rechnungen und Verträgen unterschieden.
Extraktion: Der Teil der Extraktion ermöglicht, nur bestimmte Daten aus einem Dokument zu extrahieren. Das könnten beispielsweise nur die für das Unternehmen relevanten Adressen, Beträge, aber auch Detailpositionen sein, anstatt das gesamte Dokument.
Speicherung: Damit Ihr Team die Dokumente respektive die relevanten Daten daraus jederzeit abrufen kann, ist die geordnete und sichere Speicherung der Daten wichtig.
Grössere Unternehmen haben für den Teil ihrer Dokumentenverarbeitung mit hohem Volumen heute oft Automatisierungslösungen integriert. Solche Optical Character Recognition (OCR)-Lösungen basieren auf Vorlagen. Damit eignen sie sich für starre Dokumente, dessen Strukturen nicht von der definierten Vorlage abweichen. Damit kann bereits ein Teil der Dokumentenverarbeitung automatisiert werden.
Herkömmliche OCR-Lösungen sind allerdings nicht gebaut für Dokumente mit verschiedenen Layouts und stetigen Änderungen in Form und Format. Das Template muss jedes Mal angepasst und die Maschine neu konfiguriert werden, sobald sich ein Dokument ändert. Das trifft dann ein, wenn Unternehmen mit unterschiedlichen Kunden und Partnern zusammenarbeiten.
Damit hat es sich aber noch lange nicht. Legacy OCR-Lösungen weisen weitere signifikante Limitierungen, darunter die folgenden, auf:
Integration: Die Integration in bestehende ERP- oder DMS-Systeme ist mitunter ein komplexes Unterfangen. Das erschwert nicht nur die Automatisierung in Abläufen der Dokumentenverarbeitung im Allgemeinen, sondern auch ganz spezifisch bei der Datenextraktion.
Wartung und Updates: Herkömmliche OCR-Lösungen sind meist nicht nur teuer in der Wartung, sondern können auch bei Updates, insbesondere wenn sie an spezifische Geschäftsanforderungen angepasst sind, hohe Kosten auslösen. Das schränkt die Fähigkeit von Unternehmen ein, mit dem technologischen Fortschritt Schritt zu halten und die Genauigkeit und Effizienz zu verbessern.
Genauigkeit: Sobald Dokumente in schwacher Qualität vorliegen oder handschriftliche Notizen wie Signaturen aufweisen, haben OCR-Lösungen Schwierigkeiten, Daten genau (oder überhaupt) zu identifizieren. Die Lösung extrahiert die Daten ungenau, womit Eingriffe und manuelle Korrekturen unumgänglich sind.
Diese Limitierungen haben eine erhebliche Auswirkung auf die Dokumentenverarbeitung und damit auch auf die Geschäftsabläufe und -ergebnisse. Aus diesem Grund suchen viele Unternehmen für die Dokumentenverarbeitung nach fortschrittlichen Technologien, um die Effizienz, Genauigkeit und Sicherheit zu verbessern, wertvolle Erkenntnisse aus den Daten zu gewinnen und die Arbeitsabläufe zu automatisieren.
Wenn Sie an der Evolution der Dokumentenerfassung interessiert sind: hier haben wir separat einen Artikel dazu verfasst.
Aufkommende Technologien in der Dokumentenverarbeitung

Jüngste Entwicklungen in der Dokumentenverarbeitung haben sich auf die Verbesserung der Genauigkeit und Effizienz dieser Aufgaben durch den Einsatz von Künstlicher Intelligenz (KI), Machine Learning (ML) und Natural Language Processing (NLP) konzentriert. Damit können Deep-Learning-Modelle so trainiert werden, dass sie bestimmte Datentypen aus Dokumenten mit hoher Genauigkeit erkennen und extrahieren können. NLP kann die Bedeutung und den Kontext von Text analysieren, um die Klassifizierung von Dokumenten zu verbessern.
Die Kombination dieser aufkommenden Technologien in der Dokumentenverarbeitung ist es, was wir heute meist Intelligent Document Processing (IDP) nennen. Für eine bessere Übersicht, Details und Vorteile der Technologien, welche den modernen IDP-Lösungen zugrunde liegen:
1. Künstliche Intelligenz (KI): In der Dokumentenverarbeitung wird KI dafür eingesetzt, um die Klassifizierung von Dokumenten, die Datenextraktion und die Weiterleitung von Dokumenten zu automatisieren. Zudem kann KI Muster und Anomalien in grossen Datensätzen erkennen.
Zu den Vorteilen von KI bei der Dokumentenverarbeitung gehören:
- Höhere Effizienz und Genauigkeit
- Geringere Arbeitskosten und bessere Skalierbarkeit
- Erhöhte Dokumentensicherheit durch automatische Klassifizierung
- Verbesserte Entscheidungsfindung auf der Grundlage der aus den Dokumenten gewonnenen Erkenntnisse
- Verbesserte Compliance durch die automatisierte Prüfung und Nachverfolgung von Dokumentenzugriff und -nutzung
2. Machine Learning (ML) und Deep Learning: ML ist ein Teilbereich von KI, Deep Learning wiederum ein Unterbereich von ML. In der Dokumentenverarbeitung wird ML und Deep Learning dazu verwendet, Algorithmen zu trainieren, die Muster in Dokumentenlayouts zu erkennen und zu klassifizieren und Daten aus unstrukturierten Dokumenten extrahieren.
Zu den Vorteilen von ML und Deep Learning bei der Dokumentenverarbeitung gehören:
- Reduzierte Arbeitskosten durch Automatisierung
- Verbesserte Genauigkeit bei der Dokumentenklassifizierung und Datenextraktion aus unstrukturierten Dokumenten
- Reduzierter Bedarf an manuellen Eingriffen in die Arbeitsabläufe der Dokumentenverarbeitung
- Verbesserte Entscheidungsfindung durch Erkenntnisse, die aus Datensätzen gewonnen werden
3. Natural Language Processing (NLP): NLP ist ein Teilbereich von KI, bei dem Maschinen darauf trainiert werden, menschliche Sprache zu verstehen und zu interpretieren. Bei der Dokumentenverarbeitung wird NLP dazu eingesetzt, um Dokumente anhand ihres Inhalts zu klassifizieren, um die Bedeutung von Dokumenten zu extrahieren, und die Weiterleitung von Dokumenten anhand ihres Inhalts zu automatisieren.
Zu den Vorteilen von NLP bei der Dokumentenverarbeitung gehören:
- Geringere Arbeitskosten durch Automatisierung
- Verbesserte Genauigkeit bei der Klassifizierung und Inhaltsanalyse von Dokumenten
- Verbessertes Routing von Dokumenten auf der Grundlage von Inhalt und Bedeutung
- Verbesserte Entscheidungsfindung durch Erkenntnisse, die aus Datensätzen gewonnen werden
4. Computer Vision: Computer Vision ist ein Bereich von KI, bei dem Maschinen trainiert werden, visuelle Daten wie Bilder und Videos zu interpretieren und zu verstehen. Im Bereich der Dokumentenverarbeitung wird Computer Vision zur Automatisierung von Aufgaben in Dokumentenverarbeitungs-Workflows und zur Datenextraktion und -klassifizierung eingesetzt.
Die Kombination dieser Technologien vereint in einem System als Intelligent Document Processing bieten Unternehmen erhebliche Vorteile: eine höhere Effizienz, bessere Genauigkeit, einfache Skalierbarkeit, Kosteneinsparungen, sowie eine bessere Entscheidungsfindung bei Einhaltung von Compliance sind nur einige davon.
Für einen detaillierten Einblick, was Parashift mit Machine Learning im Bereich der Dokumentenverarbeitung anders macht, empfehlen wir diese Folge des IDP Podcasts.
Die Zukunft der Dokumentenverarbeitung

Die enormen Fortschritte in der Dokumentenverarbeitung über die letzten 3-5 Jahre versprechen einiges für die Zukunft. Mindestens genauso, nur in wahrscheinlich noch rasanterer Geschwindigkeit, dürften auch die kommenden fünf Jahren von erheblichen Technologiefortschritten geprägt sein. Innovationen im Bereich der künstlichen Intelligenz und Machine Learning werden die Fähigkeiten von IDP weiter vorantreiben. Hinzu kommen “neue Hype-Phänomene” wie zuletzt OpenAIs ChatGPT, mit denen sich IDP-Anbieter auseinandersetzen müssen. Die Zukunft der Dokumentenverarbeitung könnte unter anderem folgende Faktoren beinhalten:
Vermehrte Einführung von IDP: Ganz allgemein gesehen, erkennen immer mehr Unternehmen die Vorteile von Intelligent Document Processing für ihr Wachstum und eine erfolgreiche digitale Transformation. Das wird eine verstärkte Adoption dieser Technologie im Bereich der Dokumentenverarbeitung bedeuten. Dies wiederum wird zu effizienteren und präziseren Arbeitsabläufen bei der Dokumentenverarbeitung sowie zu einer höheren Skalierbarkeit und Kosteneinsparungen für Unternehmen führen.
Anhaltendes Wachstum und Investitionen: Es wird erwartet, dass der IDP-Markt weiter wächst und die Investitionen in die Technologie zunehmen werden. Dies wird die Innovation und Entwicklung von IDP-Lösungen weiter vorantreiben und sie im Laufe der Zeit immer leistungsfähiger machen. Zudem werden Investitionen nötig sein, damit die KI-Modelle der Intelligent Document Processing-Lösung mit den komplexen Use Cases und deren Dokumentenqualität Schritt halten können.
Verstärkter Einsatz von cloudbasierten Lösungen: Cloudbasierte IDP-Lösungen werden sich immer mehr durchsetzen. Das ermöglicht es Unternehmen, auf IDP-Funktionen zuzugreifen, ohne dass sie Hardware oder Software vor Ort benötigen. Dies wird die Skalierbarkeit und Flexibilität von IDP-Lösungen erhöhen und sie auch für kleine und mittlere Unternehmen zugänglicher machen.
Konzentration auf Dokumentensicherheit und Dokumentenanalysen: Da die Menge der verarbeiteten und gespeicherten Dokumentendaten weiter zunimmt, kann eine verstärkte Konzentration auf die Dokumentensicherheit erwartet werden. Ähnliches gilt bei Dokumentenanalysen und der Aufdeckung vor Betrug durch die frühzeitige Erkennung von Anomalien und verdächtigen Mustern.
Verbessertes Kundenerlebnis: Bereits heute kann Intelligent Document Processing Geschwindigkeit und Genauigkeit von kundenorientierten Dokumentenverarbeitungsaufgaben wie beispielsweise das Claims Processing markant verbessern. Diese Möglichkeiten und positiven Auswirkungen auf das Kundenerlebnis werden in naher Zukunft nur noch grösser werden und neue Use Cases werden dazukommen.
Die Kombination von LLMs und IDP: Large Language Models (LLMs) wie OpenAIs ChatGPT sind seit Monaten in aller Munde. Während der Hype offensichtlich ist, bergen LLMs ebenfalls neue Möglichkeiten und Anwendungsfälle in Kombination mit Intelligent Document Processing. Durch generative KI kann eine Vielzahl neuer Anwendungsfälle auf der IDP-Ebene gelöst werden. Auch hier werden mit Sicherheit in Zukunft weitere Anwendungsfälle für die Dokumentenverarbeitung hinzukommen.
An der Entwicklung einer API, die alle Dokumente verarbeitet und die Daten ohne menschliches Zutun zurücksendet, arbeitet das Parashift-Team täglich. Das Ziel: die vollständig autonome Dokumentenextraktion.
Herausforderungen in der Dokumentenverarbeitung und wie Parashift diese löst

Wie bei jeder aufstrebenden Technologie wird es auch bei der intelligenten Dokumentenverarbeitung in den nächsten Jahren zu neuen Herausforderungen kommen, die es zu beachten gilt. Darunter sind die folgenden Herausforderungen und wie Parashift diese löst:
1. Datenschutz und Compliance: Bei der Dokumentenverarbeitung werden oft sensible Daten wie persönliche Informationen verarbeitet. Es muss sichergestellt werden, dass diese Daten vor unbefugtem Zugriff oder unbefugter Verwendung geschützt sind. Da die Technologien zur Dokumentenverarbeitung immer fortschrittlicher werden und in der Lage sind, sensible Informationen zu extrahieren, wird es immer mehr Bedenken hinsichtlich des Schutzes der Privatsphäre und des Datenschutzes geben. Es muss sichergestellt werden, dass diese Daten vor unbefugtem Zugriff oder Verwendung geschützt sind. Ausserdem müssen Systeme für die Dokumentenverarbeitung transparent und nachvollziehbar sein.
Wie Parashift mit dieser Herausforderung umgeht: Parashifts moderne Cloud-Infrastruktur ist vollständig EU-DSGVO-konform. Kunden weltweit nutzen Parashift für ihre sensibelsten Daten und Dokumente. EU-DSGVO und Datensicherheit sind deshalb zwei der wichtigsten Eigenschaften von Parashift. Die Plattform läuft in ISO27001, ISO27017, ISO27110, ISO27018, SOC 1/2/3, PCI DSS, CSA STAR und HIPAA-konformen Rechenzentren, was Parashift zu einem sicheren Cloud-IDP-Anbieter macht. Durch die Cloud-SaaS-Lösung kann ein globaler Service mit einem Höchstmass an Sicherheit und kontinuierlichen Softwareverbesserungen garantiert werden.
2. Kontinuierliche Verbesserungen: Es wird in naher Zukunft immer wichtiger sein, dass eine IDP-Lösung während dem Betrieb lernt und sich laufend verbessert. Nur so wird es für Unternehmen möglich sein, von exakten Daten profitieren zu können.
Wie Parashift mit dieser Herausforderung umgeht: Das Kernkonzept der Parashift IDP-Plattform ist das proprietäre Document Swarm Learning. Die Machine Learning Algorithmen, welche den “Dokumentenschwarm” antreiben, trainieren auf Milliarden von Datenpunkten und lernen stetig dazu: mit jedem Dokument, von jedem Kunden und aus jeder Industrie. Dazu werden die Dokumenttypen in einzelne Felder zerlegt, wodurch ein globales Datennetzwerk für beispiellose Out-of-the-Box-Funktionen entsteht. Diese geteilten Learnings über alle Dokumenttypen, Kunden und Branchen hinweg sorgen für maximale Effizienz. Document Swarm Learning ermöglicht es Unternehmen, automatisch Hunderte von Dokumententypen zu klassifizieren und Dokumentendaten zu extrahieren. Das ist einzigartig in der IDP-Branche.
3. Simple Benutzeroberflächen: Komplexe Benutzeroberflächen sind je länger je mehr ein No-Go. Es wird zukünftig immer wichtiger werden, dass auch Mitarbeitende mit wenig oder gar keiner Programmiererfahrung mit Systemen für die automatisierte Dokumentenverarbeitung arbeiten können.
Wie Parashift mit dieser Herausforderung umgeht: Die Parashift IDP-Plattform ist komplett nach dem No-Code Prinzip aufgebaut. Das bedeutet, dass Mitarbeitende ohne spezifisches Know-how mit der Plattform umgehen können. Vortrainierte und direkt einsatzbereite Standard Dokumenttypen können mit einem Klick aktiviert werden. Zudem können individuelle Dokumenttypen einfach selbst erstellt werden. Dank dem No-Code-Ansatz komplett ohne die Hilfe von Experten oder Entwickler.
4. Ständige Weiterentwicklung und Innovation: Für IDP-Anbieter ist es ein Muss, ihre Dokumentenverarbeitungslösungen laufend weiterzuentwickeln, zu innovieren und Kunden neue und bessere Features bereitzustellen.
Wie Parashift mit dieser Herausforderung umgeht: Parashift hat sich der laufenden Weiterentwicklung verschrieben, um Kunden bei der KI-Dokumentenverarbeitung auch in Zukunft an der Spitze der Innovation zu halten. Das zeigt sich auch an der ganzen Reiher neuer Features, die Parashift kürzlich angekündigt hat und in den nächsten sechs bis zwölf Monaten schrittweise in die IDP-Plattform integrieren wird. Unter den neuen Funktionen befinden sich: vollständig EU-DSGVO-konforme LLMs, welche das zuvor angesprochene Document Swarm Learning nutzen und so eine einzigartige Mischung aus radikaler Innovation, Datenschutz und Sicherheit bieten (speziell für Banken und Versicherungen und für das Einhalten von hohen Standards in Informationssicherheit und Compliance). Durch generative KI kann beispielsweise mit einem Klick die Zusammenfassung des jeweiligen Dokuments angefordert oder eine Interpretation des Kontexts mit einem Klick ausgegeben werden (automatisches Erkennen des Dokumententyps wie z.B. Korrespondenz). Zudem öffnet Parashift die Integration von AI-APIs von Drittanbietern wie OpenAI bei weniger Compliance-lastigen Anwendungsfällen. Das ermöglicht es Kunden, eine Vielzahl von KI-gesteuerter Diensten in ihrer bestehenden Dokumentenverarbeitungsinfrastruktur zu nutzen – ohne, dass sie sich mit Integrationsfragen befassen müssen. Ausserdem wird der Parashift Marketplace sehr bald eröffnet, womit Unternehmen Zugang zu einem One-Stop-Shop für sämtliche Anforderungen an die intelligente Dokumentenverarbeitung erhalten. Neue Automationsmöglichkeiten wie die „Wenn X dann Y“-Logik-Engine, leistungsstarke Skripting- und Berechnungsfunktionen und eine Entwicklerkomponente, die Viewer-/Validierungs-/Anmerkungsfunktionen in Drittanbieteranwendungen ermöglicht, vervollständigen die neuen Funktionen.
Der Analyst Quadrant Knowledge Solutions hat Parashift als ein Leader in seiner SPARK Matrix™ Intelligent Document Processing 2022 positioniert.
Mit der Parashift Intelligent Document Processing-Plattform liegt die Automatisierung Ihrer Dokumentenverarbeitung damit sowohl für die Gegenwart als auch für die Zukunft in besten Händen.