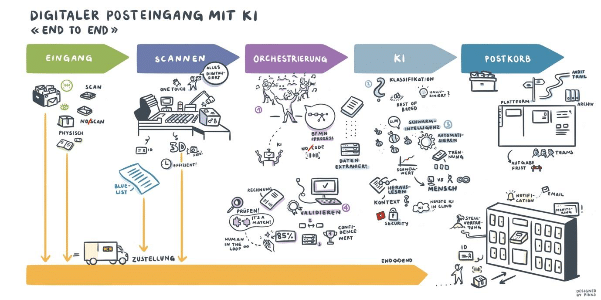
Als wir vor 2 Jahren begannen, uns mit dem Bau eines Clusters zur autonomen Verarbeitung von Buchhaltungsaufgaben zu beschäftigen, dachten wir, dass die Extraktion von Buchhaltungsbelegen eine Sache ist, welche die Industrie bereits gelöst hätte. Wie wir feststellen mussten, ist dem beileibe nicht so.
(Lesedauer 3 Minuten)
Denn als wir die ersten Lösungen im Detail anschauten, fanden wir rasch heraus, dass eine wirklich gute Extraktionsqualität nur auf sehr umständliche und mühsame Weise erreicht werden kann. Und dass viele Software-Lösungen aufwändig zu beschaffen, zu betreuen und auch teuer sind.
Ein Template pro Dokumententyp
Eine exzellente Extraktionsqualität kann denn mit herkömmlicher Technologie auch nur erzielt werden, wenn pro Dokument manuell ein Template angelegt wird. Dieser Umstand verhindert leider eine autonome Verarbeitung von Belegen.
Aus diesem Grund begannen wir sehr früh mit der Entwicklung eines Machine Learning Clusters, welcher Dokumente möglichst ohne Zutun verarbeiten kann. Auf den ersten Metern dieser Entwicklung realisierten wir, dass es bedeutend einfacher ist, als wir uns das anfänglich vorstellten. Es wurde aber, wie viele komplexe Aufgabenstellungen, je aufwändiger je weiter wir kamen.
Dokumente betrachten wie Menschen das tun
Wir gehen dabei grundlegend anders vor, als die bekannten OCR Technologien. Im Grunde genommen betrachtet unsere Technologie Dokumente wie Menschen.
Bekommen wir Menschen z. Bsp. eine Rechnung vorgelegt, die in einer uns fremden Sprache ausgestellt wurde, sind wir in der Lage zu erkennen, dass es sich überhaupt um eine Rechnung handelt. Auch erkennen wir für uns schon fast intuitiv, welche die wesentlichen Datenpunkte sind.
Das ist daher möglich, weil wir in der Regel über sehr viel Erfahrung im Umgang mit diesen Dokumenten verfügen (wenn Sie nicht das ganze Leben als, sagen wir, Gärtner gearbeitet haben). Wir erfassen in einem ersten Schritt visuell das Dokumente und können am groben Schema eine Klassifizierung des Dokuments machen. Wir müssen das Dokument nicht im Detail lesen, um zu wissen wo was auf dem Dokument ist.
Danach suchen wir uns Anhaltspunkte welche Werte auf dem Dokument zusammengehören und erst dann lesen wir die einzelne Werte im Kontext zu einander aus.
Unsere Technologie macht das im Grunde genommen genau gleich.
Von Menschen lernen
Die Maschine lernt dann besonders gut, wenn wir Menschen ihr beim Lernen helfen. Ihr in schwierigen Fällen zeigen, wo was genau ist und aufzeigen warum es so ist. Das ist bei Buchhaltungsbelegen nicht anders.
Wir erstellen also von den Dokumenten gesicherte, belastbare Datenabbilde welche wir manuell validieren und korrigieren. Dieses Set an perfekten Daten nutzen wir um die Maschine schnell zu trainieren. Wichtig ist dabei, dass sprichwörtlich das hinterste und letzte Komma korrekt ist. Wir haben schnell erkannt, dass es sehr viel Sinn ergibt, Belege mit enorm hoher Detailtreue zu erfassen.
Denn viele Leute im Machine Learning Bereich machen den Fehler, dass sie auf der einen Seite zwar viel Datenmaterial mit einbeziehen, aber zu wenig gut darauf achten, dass dieses Datenmaterial eine hohe Qualität hat.
Oft wundert man sich dann darüber, dass der Output qualitativ nicht ausreichend ist.
Lösung der Extraktion von Buchhaltungsdokumenten ist der erste bedeutende Schritt zu autonomen Buchhaltungssystemen
Warum wir uns mit der Extraktion von Buchhaltungsdokumenten befassen, hat einen simplen Grund: Wir kommen nicht darum herum es zu tun, wenn wir die autonome Buchhaltungsengine realisieren wollen. Die automatische Verbuchung von Geldkonten-Transaktionen und die Abstimmung dieses Streams mit den Belegdaten ist denn vergleichsweise simpel, aber ohne Belegdaten unmöglich.
Leider ist auch nicht absehbar, dass die elektronischen Rechnungsformate uns diesen Schritt in nützlicher Frist abnehmen würden. Bei keinem Format der Zukunft sind die Line Items, also die Rechnungsposten, verpflichtend. Das bedeutet, dass wir zwar mit einem solchen Format zwar die Standardinformationen bekommen, die für die Buchhaltung relevanten Details aber eben nicht strukturiert mitgeliefert werden (müssen).
Es ist Zeit die manuelle Arbeit in der Buchhaltung radikal zu reduzieren. Das war schon lange klar und es scheint als wäre die Branche langsam aber sicher aufgewacht und würde vermehrt in diese Richtung arbeiten.
Kosten- und Effizienzgewinne sind aber nur der erste Schritt, viel bedeutender ist, dass wir damit die Grundlage schaffen für ein Accounting, das beiläufig ist und mit der radikal verbesserten Datenbasis ganz neue Entscheidungsgrundlagen ermöglicht.
Wir sehen denn Robo-Accounting auch vor allem in diesem Kontext. Langfristig neue Wege im Accounting zu beschreiten. Damit das möglich wird, muss vermeintlich banales, wie die autonome Extraktion von Daten aus Papierbelegen, erst gelöst werden. Darum sind wir da dran.