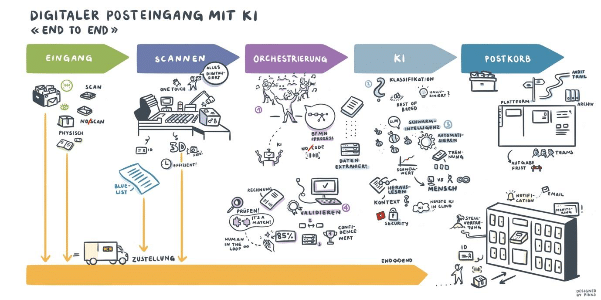
In einem der letzten Artikeln griffen wir die Relevanz von gewissen Konfigurationen im Kontext vom Dokumenten-Scanning auf. Denn wenn nicht richtig gescannt wird, kann es bei der nachfolgenden Extraktion zu Qualitätseinbussen kommen, die die angestrebten Kosteneinsparungen limitieren. Was aber genau nach dem Scanning der Dokumente passiert und wie die Daten extrahiert werden, haben wir noch nicht konkret thematisiert. Es gibt eine Reihe von Schritten, die jedes Dokument, das an die Parashift Plattform gesendet wird, durchläuft. Was bei jedem dieser Schritte passiert und in welcher Reihenfolge diese ablaufen, beschreibe ich Ihnen in folgendem Artikel näher.
Vorbereitung
Firmen erhalten Dokumente über verschiedenste Kanäle. Wie bereits im Artikel zum Thema Multichannel Document Processing beschrieben, kann es sich dabei etwa um E-Mails mit Anhang wie PDFs oder Bilddateien handeln. Daneben gibt es auch eine Vielzahl an physischen Dokumenten wie Rechnungen, Lieferscheine und Verträge, die über die Post oder Filialen ins Unternehmen kommen. All diese Dokumente müssen für die Extraktion mit Parashift erst digitalisiert werden, wenn sie es nicht bereits sind. Dafür eignet sich besonders das Early Scanning bei dem Dokumente für Weiterverarbeitungs- und Archivierungszwecke direkt nach dem Eingang gescannt und digitalisiert werden. Nachdem die Dokumente erfolgreich und mit den optimalen Einstellungen eingescannt wurden, werden sie über eine REST API an Parashift übermittelt. In einem idealen Integrationsszenario realisieren Ihre Mitarbeiter nicht einmal, dass Parashift in die Prozesse eingebunden wurde. Abgesehen davon natürlich, dass sie plötzlich nichts mehr mit der Belegerfassung zu tun haben.
Bei Parashift angekommen, wird dann zuerst ein sogenanntes Enhancement zur Qualitätsverbesserung des Inputs durchgeführt. Die Dokumente werden dabei einer Rotationskontrolle unterzogen, wo festgestellt wird, ob das Dokument allenfalls schräg eingescannt wurde. Je nachdem wird das Dokument auch noch zurechtgeschnitten und geradegerückt. Handelt es sich um Kamerafotos, werden bei Bedarf Korrekturen vorgenommen, die die nachfolgende Extraktion begünstigen. Dieser Enhancement-Prozess läuft vollkommen automatisch ab.
Ist dieser Prozess abgeschlossen, ist der nächste Schritt die optische Zeichenerkennung. Auf Englisch Optical Character Recognition (OCR). Dabei wird der komplette Text analysiert und die Daten, die sich darauf befinden, ausgelesen. Zusätzlich wird das Layout analysiert und etwaige Barcodes werden ebenfalls extrahiert.
Seitentrennung
Wurde der Text mittels OCR gelesen, geht es zum nächsten Schritt über: Der Seitentrennung. Hier wird analysiert, ob der an Parashift übermittelte Scan tatsächlich aus nur einem Dokument besteht oder ob es sich dabei um mehrere Dokumente in einem Scan handelt. Beispielsweise könnte ein 15-seitiger Scan aus 4 Rechnungen bestehen. Falls dies so wäre, dann erkennt das die Software von Parashift und behandelt sie als separate Rechnungen. Beinhaltet das Dokument leere Seiten, werden diese gelöscht. Eine kleine Anmerkung: Heute ist diese Funktionalität noch nicht in der offiziellen Version vorhanden. Sie befindet sich aber bereits in Entwicklung und wird bis Ende 2020 dann auch verfügbar sein. Das heisst, bis die Funktion integriert ist, kann die Seitentrennung noch nicht von Parashift übernommen werden und sollte unbedingt mittels anderer Anbieter oder Methoden sichergestellt werden.
Klassifizierung
Nach der Seitentrennung folgt die Klassifikation der Dokumente. Der Algorithmus bestimmt, um welche Art von Dokument es sich handelt und speichert diese Information für die kommenden Schritte ab. Als Kunde von Parashift kann nebst der Seitentrennung die Klassifikation optional aber auch selbst vorgenommen werden.
Extraktion
Basierend auf dem identifizierten Dokumententyp, werden in diesem Teil die wichtigsten Daten extrahiert. Bei einer Rechnung ist dies beispielsweise das Datum, die Adresse des Rechnungsstellers und Empfängers, dessen Mehrwertsteuernummer, IBAN, die Einzelposten sowie die verschiedenen Beträge (neben weiteren Feldern). Dieser Schritt funktioniert ohne jegliche Vorlagen oder Konfigurationsbedarf Ihrerseits. Auch sonstige manuelle Arbeit wird bei diesem Schritt nicht benötigt. Das ist somit ein wesentlicher Vorteil gegenüber der manuellen oder Vorlagen-basierten Dokumentenextraktion. Zuletzt wird in ein Quality Check durchgeführt, um zu sehen, ob sich die Engine im Ausführen ihres Jobs sicher war.
Nachbearbeitung und Archivierung
Nach erfolgreicher Extraktion der wichtigsten Daten, folgt die Nachbearbeitung. Dies ist ein Service-Offering, das Parashift ganz klar von der Konkurrenz unterscheidet. Denn sind die Daten bei der Extraktion von Parashift Standard Dokumenttypen (beispielsweise Bestellungen, Lieferscheine, Rechnungen, etc.) nicht vollständig oder falsch extrahiert worden, übernimmt Parashift die manuelle Nachbearbeitung. Die veredelten Daten werden dann wiederum mittels API an Sie beziehungsweise Ihr führendes System zurückgespielt.
Dort angelangt, können Sie dann Business Rules für die extrahierten Daten anwenden. Sie können zum Beispiel Bestellabgleiche dank der extrahierten Metadaten der Einzelposten durchführen sowie Zahlungskonditionen oder Lieferanten finden und mit dem ERP verglichen. Auch wenn es sich um neue Lieferanten handelt, werden diese dank der intelligenten OCR-Lösung, welche ohne Stammdatenabgleich arbeitet, erkannt und können automatisiert ins System aufgenommen werden. Wie dies funktioniert, habe ich in einem früheren Artikel erklärt.
Wurden dann die Business Rules angewandt und die extrahierten Daten weiterverarbeitet, so wird das Dokument schlussendlich abschliessend archiviert. Meist erfolgt diese Archivierung in einem Dokumentenmanagement-System (DMS) und symbolisiert das Ende des Lebenszyklus eines Dokumentes.