In the last blog post, we briefly covered the evolutionary history and the main advantages and disadvantages of cloud and on-premise solutions in general. In this part of the blog article series, we will now become more specific and take a closer look at those of cloud and on-premise applications in the OCR field. In this context, I will also explain how we at Parashift are taking advantage of the cloud network in order to build a global platform for autonomous document processing in the most cost-effective way. Last but not least, a summary of the two contributions follows.

Extraction quality: The cost trap
In addition to the trade-offs that need to be considered in general, which I have described before in part 1, the extraction quality is an important aspect for software solutions in the OCR field, which should be considered equally when choosing the right infrastructure. Today, after the initial setup, configuration and learning phase, traditional on-premise installations should be able to handle industry-specific standard cases. However, the extraction capabilities are limited to a certain number of different documents and layouts that you have specifically developed together with the software provider as part of the OCR software implementation project.
To increase the flexibility of the OCR or to realize further quality improvements of the extraction, which are two significantly different tasks, you are therefore more or less permanently dependent on consulting and technical support from the manufacturer. Accordingly, such endeavors are associated with considerable expenses. With additional investments and configurations, however, you should generally be able to automate special cases. If you want to achieve truly autonomous processing, this will quickly become very expensive as your marginal costs in this process increase exponentially.
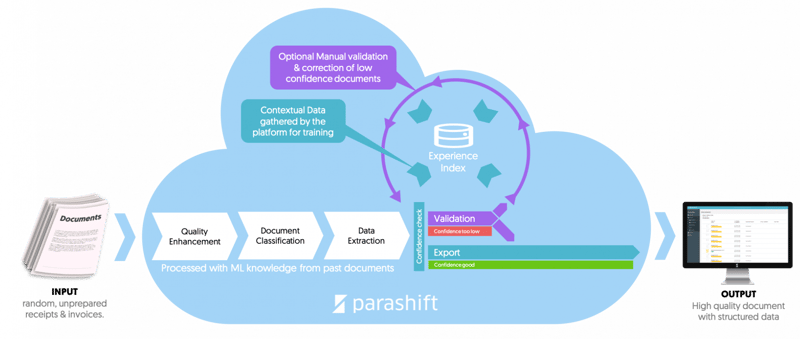
If you use a cloud OCR service instead, you can share costs and effort with all other users on the platform. In concrete terms, this means that, on the one hand, the costs incurred for the expansion of the document types, layout variations and languages supported for processing, as well as the incremental extraction improvements of the OCR engine, are borne by all customers of the service. On the other hand, the effort to be made by the individual user is also extremely minimized. This simply because you are no longer necessarily dependent on lengthy projects to further develop your OCR technology. Instead, technological advances in cloud OCR services are achieved continuously and without any additional contribution on your part as all documents processed in the cloud are used for learnings which then get shared directly with all customers in the network. For example, if one customer wants to process a document format with country-specific codes and format structures, optimize the OCR engine for full text, or improve one of the extraction methods, all other customers will be able to use this functionality immediately too.
Based on this cloud architecture, we at Parashift have aggregated a diverse range of document intelligence. We make this knowledge available to you from day one, enabling you to process over 64 standard document types without any need for templates (we are constantly expanding the range of document types supported). An initial project phase and further improvement projects are thus strongly limited and in some cases even completely obsolete. So, the underlying technologies create a reinforcement mechanism. In other words, as the data pool of documents grows, the robustness and extraction performance can be continuously improved. As a result, the extraction service will become increasingly attractive compared to the competition and more customers will want to process their documents using it. And the more customers process their documents via Parashift, the more economically attractive the solution or the optimization of performance will be for each individual customer.
Correct data from the beginning
Until an OCR system is robust enough to process any document independently of language and country and with an extraction accuracy of 99.9 percent, we need target-aimed and cost-effective validation and annotation processes that help the OCR engine in the learning process and deliver correct data. Because we are explicitly working towards autonomy and have set up the corresponding structures and processes, we can already offer fully validated data at very low cost. As a customer, you can therefore completely dispense with the conventional processes of document processing and use the resources saved here elsewhere for value-adding activities for example.
Conclusion
As you can see, SaaS solutions clearly have advantages over on-premise solutions that can be objectively measured (and put our bias for SaaS models into perspective ????). Probably the most important of these advantages are the low acquisition costs, which can be particularly exciting for small and medium-sized companies, the simple setup, the scalability, but also the possibility to outsource IT processes around the software that are not necessarily required. With OCR software, there is an additional economic advantage, since document extensions and improvements in extraction performance are massively lower and do not necessarily have to be implemented in long project work, but can be deployed into the software “on the fly” and without any special intervention. With all these advantages, it is still really important to note that if you want to keep complete control over your data or want a high degree of software customization, you should accept various trade-offs and still work with an on-premise.
